mirror of
https://github.com/funkypenguin/geek-cookbook/
synced 2026-07-24 13:13:00 +00:00
Stupid .gitignore
Signed-off-by: David Young <davidy@funkypenguin.co.nz>
This commit is contained in:
@@ -0,0 +1,131 @@
|
||||
---
|
||||
draft: true
|
||||
date: 2023-02-07
|
||||
categories:
|
||||
- note
|
||||
tags:
|
||||
- renovate
|
||||
---
|
||||
|
||||
# Consolidating multiple manager changes in Renovate PRs
|
||||
|
||||
I work on several large clusters, administered using [FluxCD](/kubernetes/deployment/flux/), which in which we carefully manage the update of Helm releases using Flux's `HelmRelease` CR.
|
||||
|
||||
Recently, we've started using [Renovate](https://github.com/renovatebot/renovate) to alert us to pending upgrades, by creating PRs when a helm update _or_ an image update in the associated helm values.yaml is available (*I like to put the upstream chart's values in to the `HelmRelease` so that changes can be tracked in one place*)
|
||||
|
||||
The problem is, it's likely that the images in a chart's `values.yaml` **will** be updated when the chart is updated, but I don't need a separate PR for each image! (*imagine a helm chart with 10 image references!*)
|
||||
|
||||
The first time I tried this, I ended up with 98 separate PRs, so I made some changes to Renovate to try to "bundle" associated helmrelease / helm values together...
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## Create a "bait" HelmRelease
|
||||
|
||||
Here's the challenge - given only a helm release version number, how do we create a file containing the helmrelease details, **and** the helm value details? Turns out that's relatively easy, since helm is able to retrieve a chart's values with `helm show values`, so I have an ansible playbook which (*per helm-chart*) retrieves these, using `helm show values {{ helm_chart_repo }}/{{ helm_chart_name }} --version {{ helm_chart_version }}`. [^1]
|
||||
|
||||
The values are inserted into a helmrelease YAML file using a template like this:
|
||||
|
||||
```yaml
|
||||
{% raw %}
|
||||
# This file exists simply to trigger renovatebot to alert us to upstream updates, and it's not
|
||||
# intended to ever be actually processed by flux
|
||||
apiVersion: helm.toolkit.fluxcd.io/v2beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: {{ helm_chart_release }}
|
||||
namespace: {{ helm_chart_namespace }}
|
||||
spec:
|
||||
chart:
|
||||
spec:
|
||||
chart: {{ helm_chart_name }}
|
||||
version: {{ helm_chart_version }}
|
||||
sourceRef:
|
||||
kind: HelmRepository
|
||||
name: {{ helm_chart_repo }}
|
||||
namespace: flux-system
|
||||
values:
|
||||
{% filter indent(width=4) %}
|
||||
{{ _helm_default_values.stdout }}
|
||||
{% endfilter %}
|
||||
{% endraw %}
|
||||
```
|
||||
|
||||
Which results in a helmrelease which looks a bit like this:
|
||||
|
||||
```yaml
|
||||
{% raw %}
|
||||
# This file exists simply to trigger renovatebot to alert us to upstream updates, and it's not
|
||||
# intended to ever be actually processed by flux
|
||||
apiVersion: helm.toolkit.fluxcd.io/v2beta1
|
||||
kind: HelmRelease
|
||||
metadata:
|
||||
name: mongodb
|
||||
namespace: mongodb
|
||||
spec:
|
||||
chart:
|
||||
spec:
|
||||
chart: mongodb
|
||||
version: 13.6.2
|
||||
sourceRef:
|
||||
kind: HelmRepository
|
||||
name: bitnami
|
||||
namespace: flux-system
|
||||
values:
|
||||
|
||||
## @section Global parameters
|
||||
## Global Docker image parameters
|
||||
|
||||
<snip for readability>
|
||||
|
||||
## Bitnami MongoDB(®) image
|
||||
## ref: https://hub.docker.com/r/bitnami/mongodb/tags/
|
||||
## @param image.registry MongoDB(®) image registry
|
||||
## @param image.repository MongoDB(®) image registry
|
||||
## @param image.tag MongoDB(®) image tag (immutable tags are recommended)
|
||||
## @param image.digest MongoDB(®) image digest in the way sha256:aa.... Please note this parameter, if set, will override the tag
|
||||
## @param image.pullPolicy MongoDB(®) image pull policy
|
||||
## @param image.pullSecrets Specify docker-registry secret names as an array
|
||||
## @param image.debug Set to true if you would like to see extra information on logs
|
||||
##
|
||||
image:
|
||||
registry: docker.io
|
||||
repository: bitnami/mongodb
|
||||
tag: 6.0.3-debian-11-r9
|
||||
{% endraw %}
|
||||
```
|
||||
|
||||
I save this helmrelease **outside** of my flux-managed folders into a folder called `renovatebait` (*I don't want to actually apply changes immediately, I just want to be told that there are changes available. There will inevitably be some "massaging" of the default values required, but now I know that an update is available.*)
|
||||
|
||||
## Alter Renovate's packageFile value
|
||||
|
||||
Just pointing renovate at this file would still create multiple PRs, since each renovate "manager" creates its PR branches independently... the secret sauce is changing the **name** of the branch renovate uses for its PRs, like this:
|
||||
|
||||
```yaml
|
||||
{% raw %}
|
||||
"flux": {
|
||||
"fileMatch": ["renovatebait/.*"]
|
||||
},
|
||||
"helm-values": {
|
||||
"fileMatch": ["renovatebait/.*"]
|
||||
},
|
||||
"branchTopic": "{{{replace 'helmrelease-' '' packageFile}}}",
|
||||
{% endraw %}
|
||||
```
|
||||
|
||||
The `branchTopic` value takes the `packageFile` name (i.e., `helmrelease-mongodb.yaml`), strips off the `helmrelease-`, and creates a PR branch named `renovate/renovatebait/mongodb.yaml`.
|
||||
|
||||
Now next time renovate runs, I get a single, nice succinct PR with a list of all the chart/images changes, like this:
|
||||
|
||||
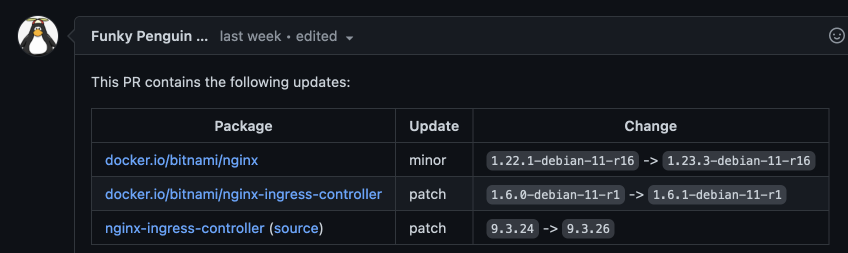
|
||||
|
||||
And an informative diff, like this:
|
||||
|
||||
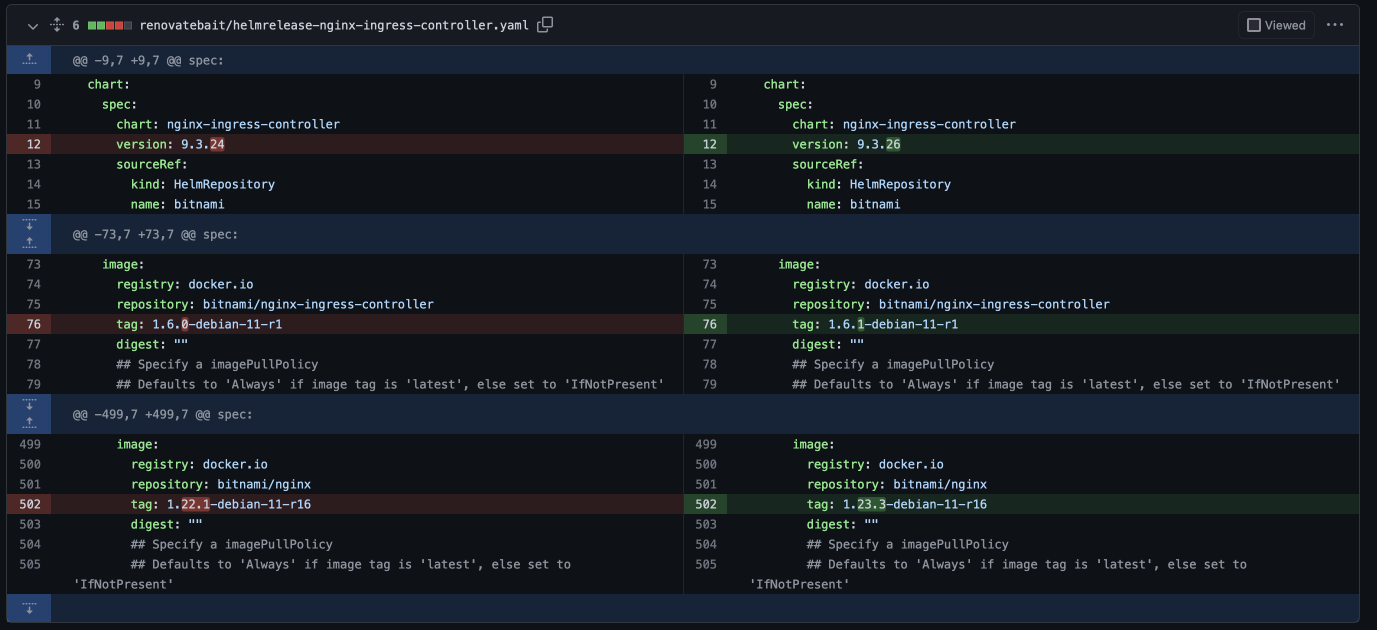
|
||||
|
||||
## Summary
|
||||
|
||||
By changing the name of the PR branch that renovate uses to create its PRs, it's possible to consolidate all the affected changes in a single PR. W00t!
|
||||
|
||||
[^1]: Yes, we ansiblize the creation of our helmreleases. It means all versions (*images and charts*) can be captured in one ansible dictionary.
|
||||
|
||||
--8<-- "blog-footer.md"
|
||||
@@ -0,0 +1,209 @@
|
||||
---
|
||||
date: 2023-02-03
|
||||
categories:
|
||||
- note
|
||||
tags:
|
||||
- kubernetes
|
||||
- velero
|
||||
---
|
||||
|
||||
# Using Velero in hardened Kubernetes with Istio
|
||||
|
||||
I'm approaching the end of the journey of applying Velero to a client's "hardened" Kubernetes cluster, and along the way I stubbed my toes on several issues, which I intend to lay out below...
|
||||
|
||||
<!-- more -->
|
||||
|
||||
## What is a hardened Kubernetes cluster?
|
||||
|
||||
In this particular case, the following apply:
|
||||
|
||||
* [X] Selective workloads/namespaces are protected by Istio, using strict mTlS
|
||||
* [X] Kyverno is employed with policies enforcing mode using the "[restricted](https://github.com/kyverno/kyverno/tree/main/charts/kyverno-policies/templates/restricted)" baseline, with further policies applied (such as deny-exec, preventing arbitrary execing into pods).
|
||||
* [X] Kubernetes best-practices are applied to all workloads, audited using Fairwinds Polaris, which includes running pods as non-root, with read-only root filesystems, whever possible.
|
||||
|
||||
## How does Velero work?
|
||||
|
||||
Velero runs within a cluster, listening for custom resources defining backups, restores, destinations, schedules, etc. Based on a combination of all of these, Velero scrapes the kubernetes API, works out what to backup, and does so, according to a schedule.
|
||||
|
||||
## Velero backup hooks
|
||||
|
||||
While Velero can backup persistent volumes using either snapshots or restic/kopia, if you're backing up in-use data, it's usually necessary to take some actions before the backup, to ensure the data is in a safe, restorable state. This is achieved using pre/post hooks, as illustrated below, a fairly generic config for postgresql instances based on Bitnami's postgresql chart [^1]:
|
||||
|
||||
```yaml
|
||||
extraVolumes: # (1)!
|
||||
- name: backup
|
||||
emptyDir: {}
|
||||
|
||||
extraVolumeMounts: # (2)!
|
||||
- name: backup
|
||||
mountPath: /scratch
|
||||
|
||||
podAnnotations:
|
||||
backup.velero.io/backup-volumes: backup
|
||||
pre.hook.backup.velero.io/command: '["/bin/bash", "-c", "PGPASSWORD=$POSTGRES_PASSWORD pg_dump -U $POSTGRES_USER -d $POSTGRES_DB -F c -f /scratch/backup.psql"]'
|
||||
pre.hook.backup.velero.io/timeout: 5m
|
||||
pre.hook.restore.velero.io/timeout: 5m
|
||||
post.hook.restore.velero.io/command: '["/bin/bash", "-c", "[ -f \"/scratch/backup.psql\" ] && \
|
||||
sleep 1m && \
|
||||
PGPASSWORD=$POSTGRES_PASSWORD pg_restore -U $POSTGRES_USER -d $POSTGRES_USER --clean \
|
||||
< /scratch/backup.psql && rm -f /scratch/backup.psql;"]' # !(3)
|
||||
```
|
||||
|
||||
1. This defines an additional ephemeral volume to attach to the pod
|
||||
2. This attaches the above volume at `/scratch`
|
||||
3. It's necessary to sleep for "a period" before attempting the restore, so that postegresql has time to start up and be ready to interact with the `pg_restore` command.
|
||||
|
||||
[^1]: Details at https://github.com/bitnami/charts/tree/main/bitnami/postgresql
|
||||
|
||||
During the process of setting up the preHooks for various iterations of a postgresql instance, I discovered that Velero will not necessary check that carefully re whether the hooks returned successfully or not. It's best to completely simulate a restore/backup of your pods by execing into the pod, and running each hook command manually, ensuring that you get the expected result.
|
||||
|
||||
## Velero vs securityContexts
|
||||
|
||||
We apply best-practice securityContexts to our pods, including enforcing of readOnly root filesystems on the pod, the disabling of all capabilities, etc. Here's a sensible example:
|
||||
|
||||
```yaml
|
||||
containerSecurityContext:
|
||||
allowPrivilegeEscalation: false
|
||||
capabilities:
|
||||
drop: ["ALL"]
|
||||
readOnlyRootFilesystem: true
|
||||
seccompProfile:
|
||||
type: RuntimeDefault
|
||||
runAsNonRoot: true
|
||||
```
|
||||
|
||||
However, on the node-restore agent, we need to make a few changes to the helm chart above:
|
||||
|
||||
```yaml
|
||||
# Extra volumes for the node-agent daemonset. Optional.
|
||||
extraVolumes:
|
||||
- name: tmp
|
||||
emptyDir:
|
||||
sizeLimit: 1Gi
|
||||
|
||||
# Extra volumeMounts for the node-agent daemonset. Optional.
|
||||
extraVolumeMounts:
|
||||
- name: tmp
|
||||
mountPath: /tmp # (1)
|
||||
|
||||
containerSecurityContext:
|
||||
allowPrivilegeEscalation: false
|
||||
capabilities:
|
||||
drop: ["ALL"]
|
||||
add: ["CHOWN"] # (2)!
|
||||
readOnlyRootFilesystem: true
|
||||
seccompProfile:
|
||||
type: RuntimeDefault
|
||||
```
|
||||
|
||||
1. node-agent tries to write a credential file to `/tmp`. We create this emptydir so that we don't need to enabel a RW filesystem for the entire container
|
||||
2. Necessary for restic restores, since after a restic restore, a CHOWN will be performed
|
||||
|
||||
## Velero vs Kyverno policies
|
||||
|
||||
We use a Kyverno policy as illustrated below this, to permit users from execing into containers. It was necessary to make an exeception to permit Velero to exec into pods:
|
||||
|
||||
```yaml
|
||||
{% raw %}
|
||||
apiVersion: kyverno.io/v1
|
||||
kind: ClusterPolicy
|
||||
metadata:
|
||||
name: deny-exec
|
||||
annotations:
|
||||
policies.kyverno.io/title: Block Pod Exec by Namespace Label
|
||||
policies.kyverno.io/category: Sample
|
||||
policies.kyverno.io/minversion: 1.4.2
|
||||
policies.kyverno.io/subject: Pod
|
||||
policies.kyverno.io/description: >-
|
||||
The `exec` command may be used to gain shell access, or run other commands, in a Pod's container. While this can
|
||||
be useful for troubleshooting purposes, it could represent an attack vector and is discouraged.
|
||||
This policy blocks Pod exec commands to Pods unless their namespace is labeled with "kyverno/permit-exec:true"
|
||||
spec:
|
||||
validationFailureAction: enforce
|
||||
background: false
|
||||
rules:
|
||||
- name: deny-exec
|
||||
match:
|
||||
resources:
|
||||
kinds:
|
||||
- PodExecOptions
|
||||
namespaceSelector:
|
||||
matchExpressions:
|
||||
- key: kyverno/permit-exec
|
||||
operator: NotIn
|
||||
values:
|
||||
- "true"
|
||||
preconditions:
|
||||
all:
|
||||
- key: "{{ request.operation || 'BACKGROUND' }}"
|
||||
operator: Equals
|
||||
value: CONNECT
|
||||
validate:
|
||||
message: Invalid request from {{ request.userInfo.username }}. Pods may not be exec'd into unless their namespace is labeled with "kyverno/permit-exec:true"
|
||||
deny:
|
||||
conditions:
|
||||
all:
|
||||
- key: "{{ request.namespace }}"
|
||||
operator: NotEquals
|
||||
value: sandbox # (1)!
|
||||
- key: "{{ request.userInfo.username }}" # (2)!
|
||||
operator: NotEquals
|
||||
value: system:serviceaccount:velero:velero-server
|
||||
{% endraw %}
|
||||
```
|
||||
|
||||
1. "sandbox" is a special, unprotected namespace for development
|
||||
2. Here we permit the velero-server service account to exec into containers, which is necessary for executing the hooks!
|
||||
|
||||
## Velero vs Istio
|
||||
|
||||
If you're running Istio sidecars on your workloads, then you may find that your hooks mysteriously fail. It turns out that this happens because Velero, by default, targets the **first** container in your pod. In the case of an Istio-augmented pod, this pod is the `istio-proxy` sidecar, which is probably not where you **intended** to run your hooks!
|
||||
|
||||
Add 2 additional annotations to your workload, as illustrated below, to tell Velero **which** container to exec into:
|
||||
|
||||
```yaml
|
||||
pre.hook.backup.velero.io/container: keycloak-postgresql # (1)!
|
||||
post.hook.restore.velero.io/container: keycloak-postgresql
|
||||
```
|
||||
|
||||
1. Set this to the value of your target container name.
|
||||
|
||||
## Velero vs Filesystem state
|
||||
|
||||
Docker-mailserver runs postfix, as well as many other components using an init-sort of process. This makes it hard to backup directly via a filesystem backup, since the various state files may be in use at any point. The solution here was to avoid directly backing up the data volume (*and no, you can't selectively exclude folders!*), and to implement the backup, once again, using pre/post hooks:
|
||||
|
||||
```yaml
|
||||
{% raw %}
|
||||
additionalVolumeMounts:
|
||||
- name: backup
|
||||
mountPath: /scratch
|
||||
|
||||
additionalVolumes:
|
||||
- name: backup
|
||||
persistentVolumeClaim:
|
||||
claimName: docker-mailserver-backup
|
||||
|
||||
pod:
|
||||
# pod.dockermailserver section refers to the configuration of the docker-mailserver pod itself. Note that teh many environment variables which define the behaviour of docker-mailserver are configured here
|
||||
dockermailserver:
|
||||
annotations:
|
||||
sidecar.istio.io/inject: "false"
|
||||
backup.velero.io/backup-volumes: backup
|
||||
pre.hook.backup.velero.io/command: '["/bin/bash", "-c", "cat /dev/null > /scratch/backup.tar.gz && tar -czf /scratch/backup.tar.gz /var/mail /var/mail-state || echo done-with-harmeless-errors"]' # (1)!
|
||||
pre.hook.backup.velero.io/timeout: 5m
|
||||
post.hook.restore.velero.io/timeout: 5m
|
||||
post.hook.restore.velero.io/command: '["/bin/bash", "-c", "[ -f \"/scratch/backup.tar.gz\" ] && tar zxfp /scratch/backup.tar.gz && rm -f /scratch/backup.tar.gz;"]'
|
||||
{% endraw %}
|
||||
```
|
||||
|
||||
1. Avoid exiting with a non-zero exit code and causing a partial failure
|
||||
|
||||
## PartiallyFailed can't be trusted
|
||||
|
||||
The Velero helm chart allows the setup of PrometheusRules, which will raise an alert in AlertManager if a backup fully (*or partially*) fails. This is what prompted our initial overhaul of our backups, since we wanted **one** alert to advise us that **all** backups were successful. Just one failure backing up one pod therefore causes the entire backup to be "PartiallyFailed", so we felt it worth investing in getting 100% success across every backup. The alternative would have been to silence the "partial" failures (*in some cases, these fail for known reasons, like empty folders*), but that would leave us blind to **new** failures, and severely compromise the entire purpose of the backups!
|
||||
|
||||
## Summary
|
||||
|
||||
In summary, Velero is a hugely useful tool, but lots of care and attention should be devoted to ensuring it **actually** works, and the state of backups should be monitored (*i.e., with `PrometheusRules` via AlertManager*).
|
||||
|
||||
--8<-- "blog-footer.md"
|
||||
Reference in New Issue
Block a user