mirror of
https://github.com/funkypenguin/geek-cookbook/
synced 2026-06-17 03:00:11 +00:00
Add markdown linting (without breaking the site this time!)
This commit is contained in:
@@ -14,9 +14,11 @@
|
||||
|
||||
## Types of changes
|
||||
<!--- What types of changes does your code introduce? Put an `x` in all the boxes that apply: -->
|
||||
<!-- ignore-task-list-start -->
|
||||
- [ ] Bug fix (non-breaking change which fixes an issue)
|
||||
- [ ] New feature (non-breaking change which adds functionality)
|
||||
- [ ] Breaking change (fix or feature that would cause existing functionality to change)
|
||||
<!-- ignore-task-list-end -->
|
||||
|
||||
## Checklist
|
||||
<!--- Go over all the following points, and put an `x` in all the boxes that apply. -->
|
||||
@@ -24,10 +26,14 @@
|
||||
|
||||
- [ ] I have read the [contribution guide](https://geek-cookbook.funkypenguin.co.nz/community/contribute/#contributing-recipes)
|
||||
- [ ] The format of my changes matches that of other recipes (*ideally it was copied from [template](/manuscript/recipes/template.md)*)
|
||||
- [ ] I've added at least one footnote to my recipe (*Chef's Notes*)
|
||||
|
||||
<!--
|
||||
delete these next checks if not adding a new recipe
|
||||
-->
|
||||
|
||||
### Recipe-specific checks
|
||||
|
||||
- [ ] I've added at least one footnote to my recipe (*Chef's Notes*)
|
||||
- [ ] I've updated `common_links.md` in the `_snippets` directory and sorted alphabetically
|
||||
- [ ] I've updated the navigation in `mkdocs.yaml` in alphabetical order
|
||||
- [ ] I've updated `CHANGELOG.md` in reverse chronological order order
|
||||
|
||||
@@ -0,0 +1,19 @@
|
||||
name: 'Lint Markdown'
|
||||
on:
|
||||
pull_request:
|
||||
types: [opened, synchronize]
|
||||
|
||||
jobs:
|
||||
lint-markdown:
|
||||
name: Lint markdown
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Lint markdown files
|
||||
uses: docker://avtodev/markdown-lint:v1 # fastest way
|
||||
with:
|
||||
config: '.markdownlint.yaml'
|
||||
args: '**/*.md'
|
||||
ignore: '_snippets' # multiple files must be separated with single space
|
||||
@@ -0,0 +1,24 @@
|
||||
name: 'mkdocs sanity check'
|
||||
on:
|
||||
pull_request:
|
||||
types: [opened, synchronize]
|
||||
|
||||
jobs:
|
||||
mkdocs-sanity-check:
|
||||
name: Check mkdocs builds successfully
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- name: Check out code
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Set up Python 3.8
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: 3.8
|
||||
architecture: x64
|
||||
|
||||
- name: Install requirements
|
||||
run: python3 -m pip install -r requirements.txt
|
||||
|
||||
- name: Test mkdocs builds
|
||||
run: python3 -m mkdocs build
|
||||
@@ -10,6 +10,6 @@ jobs:
|
||||
- uses: actions/stale@v3
|
||||
with:
|
||||
repo-token: ${{ secrets.GITHUB_TOKEN }}
|
||||
stale-issue-message: 'This issue has gone mouldy, because it has been open 30 days with no activity. Remove stale label or comment or this will be closed in 5 days'
|
||||
days-before-stale: 30
|
||||
days-before-close: 5
|
||||
stale-issue-message: 'This issue has gone mouldy, because it has been open 90 days with no activity. Remove stale label or comment or this will be closed in 14 days'
|
||||
days-before-stale: 90
|
||||
days-before-close: 14
|
||||
@@ -1,9 +0,0 @@
|
||||
{
|
||||
"MD046": {
|
||||
"style": "fenced"
|
||||
},
|
||||
"MD013": false,
|
||||
"MD024": {
|
||||
"siblings_only": true
|
||||
}
|
||||
}
|
||||
@@ -0,0 +1,17 @@
|
||||
# What's this for? This file is used by the markdownlinting extension in VSCode, as well as the GitHub actions
|
||||
# See all rules at https://github.com/DavidAnson/markdownlint/blob/main/doc/Rules.md
|
||||
|
||||
# Ignore line length
|
||||
"MD013": false
|
||||
|
||||
# Allow multiple headings with the same content provided the headings are not "siblings"
|
||||
"MD024":
|
||||
"siblings_only": true
|
||||
|
||||
# Allow trailing punctuation in headings
|
||||
"MD026": false
|
||||
|
||||
# We use fenced code blocks, but this test conflicts with the admonitions plugin we use, which relies
|
||||
# on indentation (which is then falsely detected as a code block)
|
||||
"MD046": false
|
||||
|
||||
+1
-1
@@ -1,4 +1,4 @@
|
||||
MIT License
|
||||
# MIT License
|
||||
|
||||
Copyright (c) 2021 Funky Penguin Limited
|
||||
|
||||
|
||||
@@ -9,6 +9,7 @@
|
||||
[dockerurl]: https://geek-cookbook.funkypenguin.co.nz/ha-docker-swarm/design
|
||||
[k8surl]: https://geek-cookbook.funkypenguin.co.nz/kubernetes/start
|
||||
|
||||
<!-- markdownlint-disable MD033 MD041 -->
|
||||
<div align="center">
|
||||
|
||||
[][cookbookurl]
|
||||
@@ -33,14 +34,14 @@
|
||||
|
||||
# What is this?
|
||||
|
||||
Funky Penguin's "**[Geek Cookbook](https://geek-cookbook.funkypenguin.co.nz)**" is a collection of how-to guides for establishing your own container-based self-hosting platform, using either [Docker Swarm](/ha-docker-swarm/design/) or [Kubernetes](/kubernetes/).
|
||||
Funky Penguin's "**[Geek Cookbook](https://geek-cookbook.funkypenguin.co.nz)**" is a collection of how-to guides for establishing your own container-based self-hosting platform, using either [Docker Swarm](/ha-docker-swarm/design/) or [Kubernetes](/kubernetes/).
|
||||
|
||||
Running such a platform enables you to run self-hosted tools such as [AutoPirate](/recipes/autopirate/) (*Radarr, Sonarr, NZBGet and friends*), [Plex][plex], [NextCloud][nextcloud], and includes elements such as:
|
||||
|
||||
* [Automatic SSL-secured access](/ha-docker-swarm/traefik/) to all services (*with LetsEncrypt*)
|
||||
* [SSO / authentication layer](/ha-docker-swarm/traefik-forward-auth/) to protect unsecured / vulnerable services
|
||||
* [Automated backup](/recipes/elkarbackup/) of configuration and data
|
||||
* [Monitoring and metrics](/recipes/swarmprom/) collection, graphing and alerting
|
||||
- [Automatic SSL-secured access](/ha-docker-swarm/traefik/) to all services (*with LetsEncrypt*)
|
||||
- [SSO / authentication layer](/ha-docker-swarm/traefik-forward-auth/) to protect unsecured / vulnerable services
|
||||
- [Automated backup](/recipes/elkarbackup/) of configuration and data
|
||||
- [Monitoring and metrics](/recipes/swarmprom/) collection, graphing and alerting
|
||||
|
||||
Recent updates and additions are posted on the [CHANGELOG](/CHANGELOG/), and there's a friendly community of like-minded geeks in the [Discord server](http://chat.funkypenguin.co.nz).
|
||||
|
||||
@@ -68,41 +69,40 @@ I want your [support][github_sponsor], either in the [financial][github_sponsor]
|
||||
|
||||
### Get in touch 👋
|
||||
|
||||
* Come and say hi to me and the friendly geeks in the [Discord][discord] chat or the [Discourse][discourse] forums - say hi, ask a question, or suggest a new recipe!
|
||||
* Tweet me up, I'm [@funkypenguin][twitter]! 🐦
|
||||
* [Contact me][contact] by a variety of channels
|
||||
- Come and say hi to me and the friendly geeks in the [Discord][discord] chat or the [Discourse][discourse] forums - say hi, ask a question, or suggest a new recipe!
|
||||
- Tweet me up, I'm [@funkypenguin][twitter]! 🐦
|
||||
- [Contact me][contact] by a variety of channels
|
||||
|
||||
### Buy my book 📖
|
||||
|
||||
I'm also publishing the Geek Cookbook as a formal eBook (*PDF, mobi, epub*), on Leanpub (https://leanpub.com/geek-cookbook). Buy it for as little as $5 (_which is really just a token gesture of support, since all the content is available online anyway!_) or pay what you think it's worth!
|
||||
I'm also publishing the Geek Cookbook as a formal eBook (*PDF, mobi, epub*), on Leanpub (<https://leanpub.com/geek-cookbook>). Buy it for as little as $5 (_which is really just a token gesture of support, since all the content is available online anyway!_) or pay what you think it's worth!
|
||||
|
||||
### [Sponsor][github_sponsor] / [Patronize][patreon] me ❤️
|
||||
|
||||
The best way to support this work is to become a [GitHub Sponsor](https://github.com/sponsors/funkypenguin) / [Patreon patron][patreon] (_for as little as $1/month!_) - You get :
|
||||
|
||||
* warm fuzzies,
|
||||
* access to the pre-mix repo,
|
||||
* an anonymous plug you can pull at any time,
|
||||
* and a bunch more loot based on tier
|
||||
- warm fuzzies,
|
||||
- access to the pre-mix repo,
|
||||
- an anonymous plug you can pull at any time,
|
||||
- and a bunch more loot based on tier
|
||||
|
||||
.. and I get some pocket money every month to buy wine, cheese, and cryptocurrency! 🍷 💰
|
||||
|
||||
Impulsively **[click here (NOW quick do it!)][github_sponsor]** to [sponsor me][github_sponsor] via GitHub, or [patronize me via Patreon][patreon]!
|
||||
|
||||
|
||||
### Work with me 🤝
|
||||
|
||||
Need some Cloud / Microservices / DevOps / Infrastructure design work done? I'm a full-time [AWS Certified Solution Architect (Professional)][aws_cert], a [CNCF-Certified Kubernetes Administrator](https://www.youracclaim.com/badges/cd307d51-544b-4bc6-97b0-9015e40df40d/public_url) and [Application Developer](https://www.youracclaim.com/badges/9ed9280a-fb92-46ca-b307-8f74a2cccf1d/public_url) - this stuff is my bread and butter! :bread: :fork_and_knife: [Get in touch][contact], and let's talk business!
|
||||
|
||||
[plex]: https://www.plex.tv/
|
||||
[plex]: https://www.plex.tv/
|
||||
[nextcloud]: https://nextcloud.com/
|
||||
[wordpress]: https://wordpress.org/
|
||||
[ghost]: https://ghost.io/
|
||||
[wordpress]: https://wordpress.org/
|
||||
[ghost]: https://ghost.io/
|
||||
[discord]: http://chat.funkypenguin.co.nz
|
||||
[patreon]: https://www.patreon.com/bePatron?u=6982506
|
||||
[patreon]: https://www.patreon.com/bePatron?u=6982506
|
||||
[github_sponsor]: https://github.com/sponsors/funkypenguin
|
||||
[github]: https://github.com/sponsors/funkypenguin
|
||||
[discourse]: https://discourse.geek-kitchen.funkypenguin.co.nz/
|
||||
[twitter]: https://twitter.com/funkypenguin
|
||||
[contact]: https://www.funkypenguin.co.nz
|
||||
[aws_cert]: https://www.youracclaim.com/badges/a0c4a196-55ab-4472-b46b-b610b44dc00f/public_url
|
||||
[discourse]: https://discourse.geek-kitchen.funkypenguin.co.nz/
|
||||
[twitter]: https://twitter.com/funkypenguin
|
||||
[contact]: https://www.funkypenguin.co.nz
|
||||
[aws_cert]: https://www.youracclaim.com/badges/a0c4a196-55ab-4472-b46b-b610b44dc00f/public_url
|
||||
|
||||
@@ -28,8 +28,8 @@ Recipe | Description
|
||||
|
||||
Also available via:
|
||||
|
||||
* Mastodon: https://mastodon.social/@geekcookbook_changes
|
||||
* RSS: https://mastodon.social/@geekcookbook_changes.rss
|
||||
* Mastodon: <https://mastodon.social/@geekcookbook_changes>
|
||||
* RSS: <https://mastodon.social/@geekcookbook_changes.rss>
|
||||
* The #changelog channel in our [Discord server](http://chat.funkypenguin.co.nz)
|
||||
|
||||
--8<-- "common-links.md"
|
||||
--8<-- "common-links.md"
|
||||
|
||||
@@ -8,4 +8,4 @@
|
||||
|
||||
## Conventions
|
||||
|
||||
1. When creating swarm networks, we always explicitly set the subnet in the overlay network, to avoid potential conflicts (_which docker won't prevent, but which will generate errors_) (https://github.com/moby/moby/issues/26912)
|
||||
1. When creating swarm networks, we always explicitly set the subnet in the overlay network, to avoid potential conflicts (_which docker won't prevent, but which will generate errors_) (<https://github.com/moby/moby/issues/26912>)
|
||||
|
||||
@@ -126,7 +126,7 @@ the community.
|
||||
|
||||
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
|
||||
version 2.0, available at
|
||||
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
|
||||
<https://www.contributor-covenant.org/version/2/0/code_of_conduct.html>.
|
||||
|
||||
Community Impact Guidelines were inspired by [Mozilla's code of conduct
|
||||
enforcement ladder](https://github.com/mozilla/diversity).
|
||||
@@ -134,5 +134,5 @@ enforcement ladder](https://github.com/mozilla/diversity).
|
||||
[homepage]: https://www.contributor-covenant.org
|
||||
|
||||
For answers to common questions about this code of conduct, see the FAQ at
|
||||
https://www.contributor-covenant.org/faq. Translations are available at
|
||||
https://www.contributor-covenant.org/translations.
|
||||
<https://www.contributor-covenant.org/faq>. Translations are available at
|
||||
<https://www.contributor-covenant.org/translations>.
|
||||
|
||||
@@ -15,7 +15,7 @@ Sponsor [your chef](https://github.com/sponsors/funkypenguin) :heart:, or [join
|
||||
|
||||
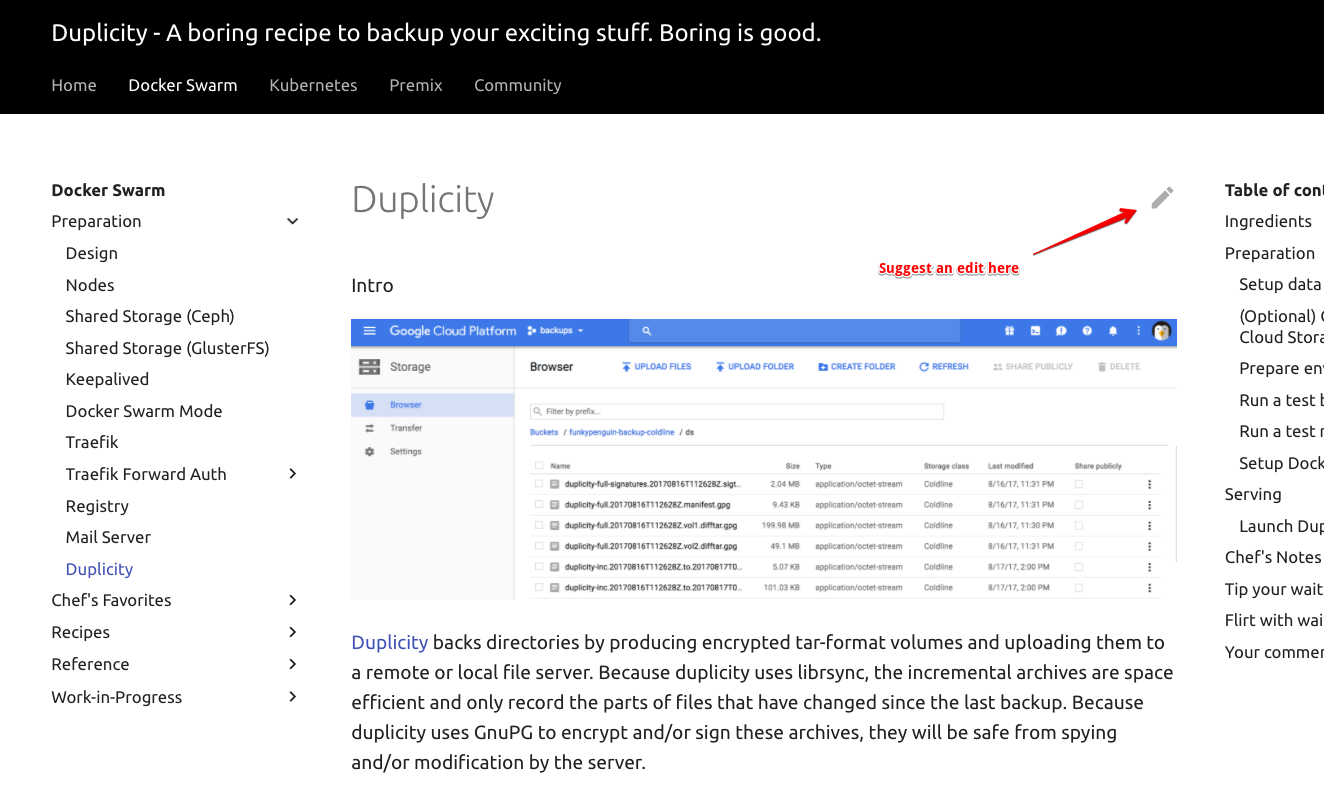
Found a typo / error in a recipe? Each recipe includes a link to make the fix, directly on GitHub:
|
||||
|
||||
|
||||

|
||||
|
||||
Click the link to edit the recipe in Markdown format, and save to create a pull request!
|
||||
|
||||
@@ -37,11 +37,11 @@ GitPod (free up to 50h/month) is by far the smoothest and most slick way to edi
|
||||
|
||||
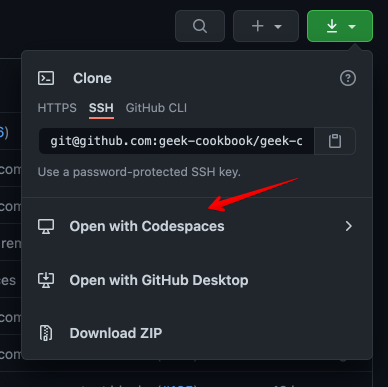
[GitHub Codespaces](https://github.com/features/codespaces) (_no longer free now that it's out of beta_) provides a browser-based VSCode interface, pre-configured for your development environment. For no-hassle contributions to the cookbook with realtime previews, visit the [repo](https://github.com/geek-cookbook/geek-cookbook), and when clicking the download button (*where you're usually get the URL to clone a repo*), click on "**Open with CodeSpaces**" instead:
|
||||
|
||||
|
||||

|
||||
|
||||
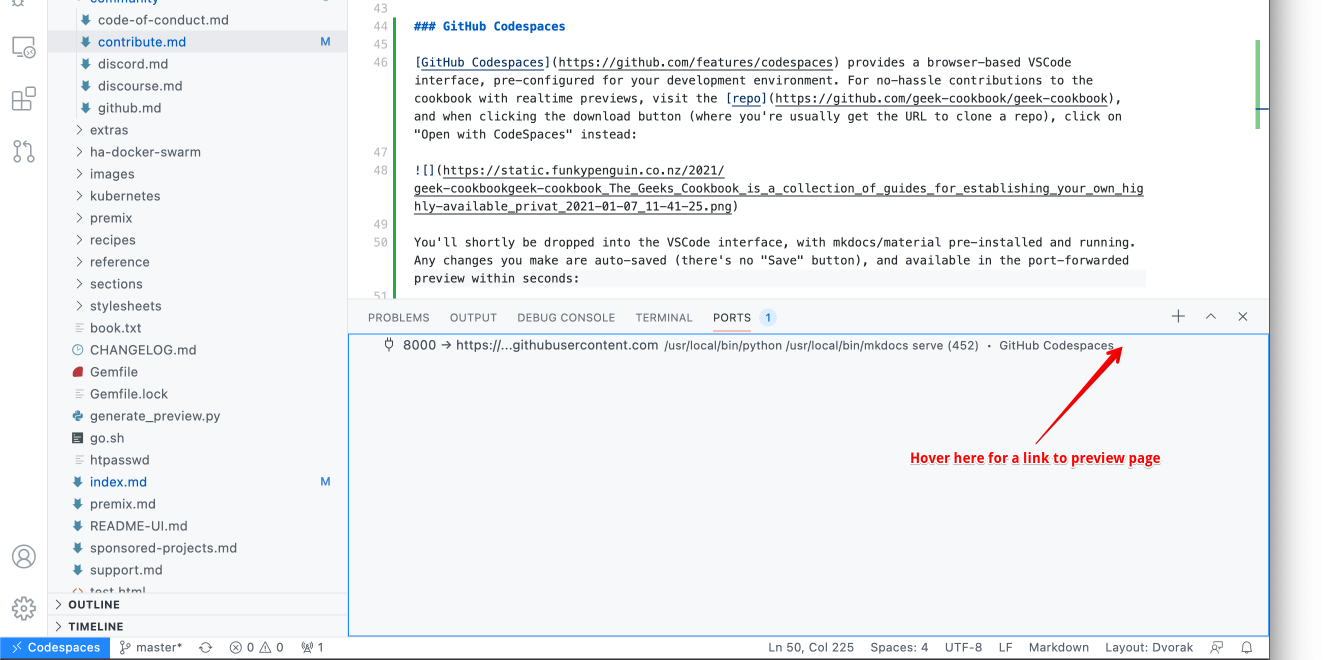
You'll shortly be dropped into the VSCode interface, with mkdocs/material pre-installed and running. Any changes you make are auto-saved (*there's no "Save" button*), and available in the port-forwarded preview within seconds:
|
||||
|
||||
|
||||

|
||||
|
||||
Once happy with your changes, drive VSCode as normal to create a branch, commit, push, and create a pull request. You can also abandon the browser window at any time, and return later to pick up where you left off (*even on a different device!*)
|
||||
|
||||
@@ -52,18 +52,15 @@ The process is basically:
|
||||
1. [Fork the repo](https://help.github.com/en/github/getting-started-with-github/fork-a-repo)
|
||||
2. Clone your forked repo locally
|
||||
3. Make a new branch for your recipe (*not strictly necessary, but it helps to differentiate multiple in-flight recipes*)
|
||||
4. Create your new recipe as a markdown file within the existing structure of the [manuscript folder](https://github.com/geek-cookbook/geek-cookbook/tree/master/manuscript)
|
||||
4. Create your new recipe as a markdown file within the existing structure of the [manuscript folder](https://github.com/geek-cookbook/geek-cookbook/tree/master/manuscript)
|
||||
5. Add your recipe to the navigation by editing [mkdocs.yml](https://github.com/geek-cookbook/geek-cookbook/blob/master/mkdocs.yml#L32)
|
||||
6. Test locally by running `./scripts/serve.sh` in the repo folder (*this launches a preview in Docker*), and navigating to http://localhost:8123
|
||||
6. Test locally by running `./scripts/serve.sh` in the repo folder (*this launches a preview in Docker*), and navigating to <http://localhost:8123>
|
||||
7. Rinse and repeat until you're ready to submit a PR
|
||||
8. Create a pull request via the GitHub UI
|
||||
9. The pull request will trigger the creation of a preview environment, as illustrated below. Use the deploy preview to confirm that your recipe is as tasty as possible!
|
||||
|
||||
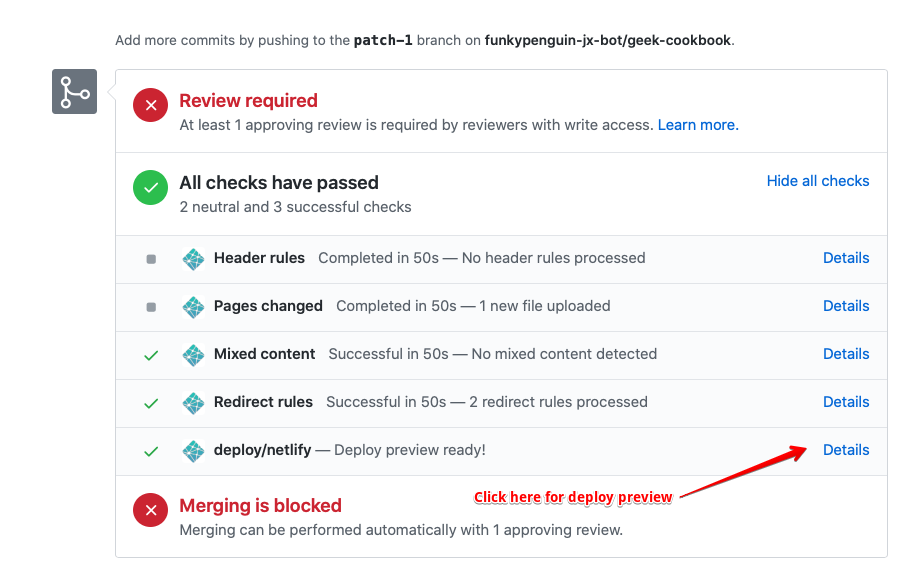
|
||||
|
||||
|
||||

|
||||
|
||||
## Contributing skillz 💪
|
||||
|
||||
Got mad skillz, but neither the time nor inclination for recipe-cooking? [Scan the GitHub contributions page](https://github.com/geek-cookbook/geek-cookbook/contribute), [Discussions](https://github.com/geek-cookbook/geek-cookbook/discussions), or jump into [Discord](/community/discord/) or [Discourse](/community/discourse/), and help your fellow geeks with their questions, or just hang out bump up our member count!
|
||||
|
||||
|
||||
@@ -15,8 +15,7 @@ Yeah, I know. I also thought Discord was just for the gamer kids, but it turns o
|
||||
|
||||
1. Create [an account](https://discordapp.com)
|
||||
2. [Join the geek party](http://chat.funkypenguin.co.nz)!
|
||||
|
||||
|
||||
<!-- markdownlint-disable MD033 -->
|
||||
<iframe src="https://discordapp.com/widget?id=396055506072109067&theme=dark" width="350" height="400" allowtransparency="true" frameborder="0"></iframe>
|
||||
|
||||
## Code of Conduct
|
||||
@@ -25,7 +24,7 @@ With the goal of creating a safe and inclusive community, we've adopted the [Con
|
||||
|
||||
### Reporting abuse
|
||||
|
||||
To report a violation of our code of conduct in our Discord server, type `!report <thing to report>` in any channel.
|
||||
To report a violation of our code of conduct in our Discord server, type `!report <thing to report>` in any channel.
|
||||
|
||||
Your report message will immediately be deleted from the channel, and an alert raised to moderators, who will address the issue as detailed in the [enforcement guidelines](/community/code-of-conduct/#enforcement-guidelines).
|
||||
|
||||
@@ -41,7 +40,7 @@ Your report message will immediately be deleted from the channel, and an alert r
|
||||
| #premix-updates | Updates on all pushes to the master branch of the premix |
|
||||
| #discourse-updates | Updates to Discourse topics |
|
||||
|
||||
### 💬 Discussion
|
||||
### 💬 Discussion
|
||||
|
||||
| Channel Name | Channel Use |
|
||||
|----------------|----------------------------------------------------------|
|
||||
@@ -55,22 +54,20 @@ Your report message will immediately be deleted from the channel, and an alert r
|
||||
| #advertisements | In here you can advertise your stream, services or websites, at a limit of 2 posts per day |
|
||||
| #dev | Used for collaboratio around current development. |
|
||||
|
||||
|
||||
### Suggestions
|
||||
### Suggestions
|
||||
|
||||
| Channel Name | Channel Use |
|
||||
|--------------|-------------------------------------|
|
||||
| #in-flight | A list of all suggestions in-flight |
|
||||
| #completed | A list of completed suggestions |
|
||||
|
||||
### Music
|
||||
### Music
|
||||
|
||||
| Channel Name | Channel Use |
|
||||
|------------------|-----------------------------------|
|
||||
| #music | DJs go here to control music |
|
||||
| #listen-to-music | Jump in here to rock out to music |
|
||||
|
||||
|
||||
## How to get help.
|
||||
|
||||
If you need assistance at any time there are a few commands that you can run in order to get help.
|
||||
@@ -79,12 +76,11 @@ If you need assistance at any time there are a few commands that you can run in
|
||||
|
||||
`!faq` Shows frequently asked questions.
|
||||
|
||||
|
||||
## Spread the love (inviting others)
|
||||
|
||||
Invite your co-geeks to Discord by:
|
||||
|
||||
1. Sending them a link to http://chat.funkypenguin.co.nz, or
|
||||
1. Sending them a link to <http://chat.funkypenguin.co.nz>, or
|
||||
2. Right-click on the Discord server name and click "Invite People"
|
||||
|
||||
## Formatting your message
|
||||
@@ -100,8 +96,3 @@ Discord supports minimal message formatting using [markdown](https://support.dis
|
||||
2. Find the #in-flight channel (*also under **Suggestions***), and confirm that your suggestion isn't already in-flight (*but not completed yet*)
|
||||
3. In any channel, type `!suggest [your suggestion goes here]`. A post will be created in #in-flight for other users to vote on your suggestion. Suggestions change color as more users vote on them.
|
||||
4. When your suggestion is completed (*or a decision has been made*), you'll receive a DM from carl-bot
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
# Discourse
|
||||
|
||||
You've found an intentionally un-linked page! This page is under construction, and will be up shortly. In the meantime, head to https://discourse.geek-kitchen.funkypenguin.co.nz!
|
||||
|
||||
You've found an intentionally un-linked page! This page is under construction, and will be up shortly. In the meantime, head to <https://discourse.geek-kitchen.funkypenguin.co.nz>!
|
||||
|
||||
@@ -1,4 +1,3 @@
|
||||
# GitHub
|
||||
|
||||
You've found an intentionally un-linked page! This page is under construction, and will be up shortly. In the meantime, head to https://github.com/geek-cookbook/geek-cookbook!
|
||||
|
||||
You've found an intentionally un-linked page! This page is under construction, and will be up shortly. In the meantime, head to <https://github.com/geek-cookbook/geek-cookbook>!
|
||||
|
||||
@@ -10,7 +10,7 @@ In the design described below, our "private cloud" platform is:
|
||||
|
||||
## Design Decisions
|
||||
|
||||
**Where possible, services will be highly available.**
|
||||
### Where possible, services will be highly available.**
|
||||
|
||||
This means that:
|
||||
|
||||
@@ -39,8 +39,7 @@ Under this design, the only inbound connections we're permitting to our docker s
|
||||
### Authentication
|
||||
|
||||
* Where the hosted application provides a trusted level of authentication (*i.e., [NextCloud](/recipes/nextcloud/)*), or where the application requires public exposure (*i.e. [Privatebin](/recipes/privatebin/)*), no additional layer of authentication will be required.
|
||||
* Where the hosted application provides inadequate (*i.e. [NZBGet](/recipes/autopirate/nzbget/)*) or no authentication (*i.e. [Gollum](/recipes/gollum/)*), a further authentication against an OAuth provider will be required.
|
||||
|
||||
* Where the hosted application provides inadequate (*i.e. [NZBGet](/recipes/autopirate/nzbget/)*) or no authentication (*i.e. [Gollum](/recipes/gollum/)*), a further authentication against an OAuth provider will be required.
|
||||
|
||||
## High availability
|
||||
|
||||
@@ -78,7 +77,6 @@ When the failed (*or upgraded*) host is restored to service, the following is il
|
||||
* Existing containers which were migrated off the node are not migrated backend
|
||||
* Keepalived VIP regains full redundancy
|
||||
|
||||
|
||||

|
||||
|
||||
### Total cluster failure
|
||||
@@ -91,4 +89,4 @@ In summary, although I suffered an **unplanned power outage to all of my infrast
|
||||
|
||||
[^1]: Since there's no impact to availability, I can fix (or just reinstall) the failed node whenever convenient.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -6,7 +6,7 @@ For truly highly-available services with Docker containers, we need an orchestra
|
||||
|
||||
!!! summary
|
||||
Existing
|
||||
|
||||
|
||||
* [X] 3 x nodes (*bare-metal or VMs*), each with:
|
||||
* A mainstream Linux OS (*tested on either [CentOS](https://www.centos.org) 7+ or [Ubuntu](http://releases.ubuntu.com) 16.04+*)
|
||||
* At least 2GB RAM
|
||||
@@ -19,19 +19,20 @@ For truly highly-available services with Docker containers, we need an orchestra
|
||||
|
||||
Add some handy bash auto-completion for docker. Without this, you'll get annoyed that you can't autocomplete ```docker stack deploy <blah> -c <blah.yml>``` commands.
|
||||
|
||||
```
|
||||
```bash
|
||||
cd /etc/bash_completion.d/
|
||||
curl -O https://raw.githubusercontent.com/docker/cli/b75596e1e4d5295ac69b9934d1bd8aff691a0de8/contrib/completion/bash/docker
|
||||
```
|
||||
|
||||
Install some useful bash aliases on each host
|
||||
```
|
||||
|
||||
```bash
|
||||
cd ~
|
||||
curl -O https://raw.githubusercontent.com/funkypenguin/geek-cookbook/master/examples/scripts/gcb-aliases.sh
|
||||
echo 'source ~/gcb-aliases.sh' >> ~/.bash_profile
|
||||
```
|
||||
|
||||
## Serving
|
||||
## Serving
|
||||
|
||||
### Release the swarm!
|
||||
|
||||
@@ -39,7 +40,7 @@ Now, to launch a swarm. Pick a target node, and run `docker swarm init`
|
||||
|
||||
Yeah, that was it. Seriously. Now we have a 1-node swarm.
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@ds1 ~]# docker swarm init
|
||||
Swarm initialized: current node (b54vls3wf8xztwfz79nlkivt8) is now a manager.
|
||||
|
||||
@@ -56,7 +57,7 @@ To add a manager to this swarm, run 'docker swarm join-token manager' and follow
|
||||
|
||||
Run `docker node ls` to confirm that you have a 1-node swarm:
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@ds1 ~]# docker node ls
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
b54vls3wf8xztwfz79nlkivt8 * ds1.funkypenguin.co.nz Ready Active Leader
|
||||
@@ -67,7 +68,7 @@ Note that when you run `docker swarm init` above, the CLI output gives youe a co
|
||||
|
||||
On the first swarm node, generate the necessary token to join another manager by running ```docker swarm join-token manager```:
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@ds1 ~]# docker swarm join-token manager
|
||||
To add a manager to this swarm, run the following command:
|
||||
|
||||
@@ -80,8 +81,7 @@ To add a manager to this swarm, run the following command:
|
||||
|
||||
Run the command provided on your other nodes to join them to the swarm as managers. After addition of a node, the output of ```docker node ls``` (on either host) should reflect all the nodes:
|
||||
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@ds2 davidy]# docker node ls
|
||||
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
|
||||
b54vls3wf8xztwfz79nlkivt8 ds1.funkypenguin.co.nz Ready Active Leader
|
||||
@@ -97,14 +97,14 @@ To address this, we'll run the "[meltwater/docker-cleanup](https://github.com/me
|
||||
|
||||
First, create `docker-cleanup.env` (_mine is under `/var/data/config/docker-cleanup`_), and exclude container images we **know** we want to keep:
|
||||
|
||||
```
|
||||
```bash
|
||||
KEEP_IMAGES=traefik,keepalived,docker-mailserver
|
||||
DEBUG=1
|
||||
```
|
||||
|
||||
Then create a docker-compose.yml as follows:
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
@@ -137,7 +137,7 @@ If your swarm runs for a long time, you might find yourself running older contai
|
||||
|
||||
Create `/var/data/config/shepherd/shepherd.env` as follows:
|
||||
|
||||
```
|
||||
```bash
|
||||
# Don't auto-update Plex or Emby (or Jellyfin), I might be watching a movie! (Customize this for the containers you _don't_ want to auto-update)
|
||||
BLACKLIST_SERVICES="plex_plex emby_emby jellyfin_jellyfin"
|
||||
# Run every 24 hours. Note that SLEEP_TIME appears to be in seconds.
|
||||
@@ -146,7 +146,7 @@ SLEEP_TIME=86400
|
||||
|
||||
Then create /var/data/config/shepherd/shepherd.yml as follows:
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
@@ -175,4 +175,4 @@ What have we achieved?
|
||||
|
||||
* [X] [Docker swarm cluster](/ha-docker-swarm/design/)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -34,7 +34,7 @@ On all nodes which will participate in keepalived, we need the "ip_vs" kernel mo
|
||||
|
||||
Set this up once-off for both the primary and secondary nodes, by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
echo "modprobe ip_vs" >> /etc/modules
|
||||
modprobe ip_vs
|
||||
```
|
||||
@@ -43,14 +43,13 @@ modprobe ip_vs
|
||||
|
||||
Assuming your IPs are as follows:
|
||||
|
||||
```
|
||||
* 192.168.4.1 : Primary
|
||||
* 192.168.4.2 : Secondary
|
||||
* 192.168.4.3 : Virtual
|
||||
```
|
||||
- 192.168.4.1 : Primary
|
||||
- 192.168.4.2 : Secondary
|
||||
- 192.168.4.3 : Virtual
|
||||
|
||||
Run the following on the primary
|
||||
```
|
||||
|
||||
```bash
|
||||
docker run -d --name keepalived --restart=always \
|
||||
--cap-add=NET_ADMIN --cap-add=NET_BROADCAST --cap-add=NET_RAW --net=host \
|
||||
-e KEEPALIVED_UNICAST_PEERS="#PYTHON2BASH:['192.168.4.1', '192.168.4.2']" \
|
||||
@@ -60,7 +59,8 @@ docker run -d --name keepalived --restart=always \
|
||||
```
|
||||
|
||||
And on the secondary[^2]:
|
||||
```
|
||||
|
||||
```bash
|
||||
docker run -d --name keepalived --restart=always \
|
||||
--cap-add=NET_ADMIN --cap-add=NET_BROADCAST --cap-add=NET_RAW --net=host \
|
||||
-e KEEPALIVED_UNICAST_PEERS="#PYTHON2BASH:['192.168.4.1', '192.168.4.2']" \
|
||||
@@ -73,7 +73,6 @@ docker run -d --name keepalived --restart=always \
|
||||
|
||||
That's it. Each node will talk to the other via unicast (*no need to un-firewall multicast addresses*), and the node with the highest priority gets to be the master. When ingress traffic arrives on the master node via the VIP, docker's routing mesh will deliver it to the appropriate docker node.
|
||||
|
||||
|
||||
## Summary
|
||||
|
||||
What have we achieved?
|
||||
@@ -88,4 +87,4 @@ What have we achieved?
|
||||
[^1]: Some hosting platforms (*OpenStack, for one*) won't allow you to simply "claim" a virtual IP. Each node is only able to receive traffic targetted to its unique IP, unless certain security controls are disabled by the cloud administrator. In this case, keepalived is not the right solution, and a platform-specific load-balancing solution should be used. In OpenStack, this is Neutron's "Load Balancer As A Service" (LBAAS) component. AWS, GCP and Azure would likely include similar protections.
|
||||
[^2]: More than 2 nodes can participate in keepalived. Simply ensure that each node has the appropriate priority set, and the node with the highest priority will become the master.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -16,7 +16,6 @@ Let's start building our cluster. You can use either bare-metal machines or virt
|
||||
* At least 20GB disk space (_but it'll be tight_)
|
||||
* [ ] Connectivity to each other within the same subnet, and on a low-latency link (_i.e., no WAN links_)
|
||||
|
||||
|
||||
## Preparation
|
||||
|
||||
### Permit connectivity
|
||||
@@ -27,7 +26,7 @@ Most modern Linux distributions include firewall rules which only only permit mi
|
||||
|
||||
Add something like this to `/etc/sysconfig/iptables`:
|
||||
|
||||
```
|
||||
```bash
|
||||
# Allow all inter-node communication
|
||||
-A INPUT -s 192.168.31.0/24 -j ACCEPT
|
||||
```
|
||||
@@ -38,7 +37,7 @@ And restart iptables with ```systemctl restart iptables```
|
||||
|
||||
Install the (*non-default*) persistent iptables tools, by running `apt-get install iptables-persistent`, establishing some default rules (*dkpg will prompt you to save current ruleset*), and then add something like this to `/etc/iptables/rules.v4`:
|
||||
|
||||
```
|
||||
```bash
|
||||
# Allow all inter-node communication
|
||||
-A INPUT -s 192.168.31.0/24 -j ACCEPT
|
||||
```
|
||||
@@ -49,17 +48,15 @@ And refresh your running iptables rules with `iptables-restore < /etc/iptables/r
|
||||
|
||||
Depending on your hosting environment, you may have DNS automatically setup for your VMs. If not, it's useful to set up static entries in /etc/hosts for the nodes. For example, I setup the following:
|
||||
|
||||
```
|
||||
192.168.31.11 ds1 ds1.funkypenguin.co.nz
|
||||
192.168.31.12 ds2 ds2.funkypenguin.co.nz
|
||||
192.168.31.13 ds3 ds3.funkypenguin.co.nz
|
||||
```
|
||||
- 192.168.31.11 ds1 ds1.funkypenguin.co.nz
|
||||
- 192.168.31.12 ds2 ds2.funkypenguin.co.nz
|
||||
- 192.168.31.13 ds3 ds3.funkypenguin.co.nz
|
||||
|
||||
### Set timezone
|
||||
|
||||
Set your local timezone, by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
ln -sf /usr/share/zoneinfo/<your timezone> /etc/localtime
|
||||
```
|
||||
|
||||
@@ -69,11 +66,11 @@ After completing the above, you should have:
|
||||
|
||||
!!! summary "Summary"
|
||||
Deployed in this recipe:
|
||||
|
||||
|
||||
* [X] 3 x nodes (*bare-metal or VMs*), each with:
|
||||
* A mainstream Linux OS (*tested on either [CentOS](https://www.centos.org) 7+ or [Ubuntu](http://releases.ubuntu.com) 16.04+*)
|
||||
* At least 2GB RAM
|
||||
* At least 20GB disk space (_but it'll be tight_)
|
||||
* [X] Connectivity to each other within the same subnet, and on a low-latency link (_i.e., no WAN links_)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -18,7 +18,7 @@ The registry mirror runs as a swarm stack, using a simple docker-compose.yml. Cu
|
||||
|
||||
Create /var/data/config/registry/registry.yml as follows:
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
@@ -48,7 +48,7 @@ We create this registry without consideration for SSL, which will fail if we att
|
||||
|
||||
Create /var/data/registry/registry-mirror-config.yml as follows:
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: 0.1
|
||||
log:
|
||||
fields:
|
||||
@@ -83,7 +83,7 @@ Launch the registry stack by running `docker stack deploy registry -c <path-to-d
|
||||
|
||||
To tell docker to use the registry mirror, and (_while we're here_) in order to be able to watch the logs of any service from any manager node (_an experimental feature in the current Atomic docker build_), edit **/etc/docker-latest/daemon.json** on each node, and change from:
|
||||
|
||||
```
|
||||
```json
|
||||
{
|
||||
"log-driver": "journald",
|
||||
"signature-verification": false
|
||||
@@ -92,7 +92,7 @@ To tell docker to use the registry mirror, and (_while we're here_) in order to
|
||||
|
||||
To:
|
||||
|
||||
```
|
||||
```json
|
||||
{
|
||||
"log-driver": "journald",
|
||||
"signature-verification": false,
|
||||
@@ -103,11 +103,11 @@ To:
|
||||
|
||||
Then restart docker by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
systemctl restart docker-latest
|
||||
```
|
||||
|
||||
!!! tip ""
|
||||
Note the extra comma required after "false" above
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -29,7 +29,7 @@ One of your nodes will become the cephadm "master" node. Although all nodes will
|
||||
|
||||
Run the following on the ==master== node:
|
||||
|
||||
```
|
||||
```bash
|
||||
MYIP=`ip route get 1.1.1.1 | grep -oP 'src \K\S+'`
|
||||
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm
|
||||
chmod +x cephadm
|
||||
@@ -44,7 +44,7 @@ The process takes about 30 seconds, after which, you'll have a MVC (*Minimum Via
|
||||
??? "Example output from a fresh cephadm bootstrap"
|
||||
```
|
||||
root@raphael:~# MYIP=`ip route get 1.1.1.1 | grep -oP 'src \K\S+'`
|
||||
root@raphael:~# curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm
|
||||
root@raphael:~# curl --silent --remote-name --location <https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm>
|
||||
|
||||
root@raphael:~# chmod +x cephadm
|
||||
root@raphael:~# mkdir -p /etc/ceph
|
||||
@@ -130,7 +130,6 @@ The process takes about 30 seconds, after which, you'll have a MVC (*Minimum Via
|
||||
root@raphael:~#
|
||||
```
|
||||
|
||||
|
||||
### Prepare other nodes
|
||||
|
||||
It's now necessary to tranfer the following files to your ==other== nodes, so that cephadm can add them to your cluster, and so that they'll be able to mount the cephfs when we're done:
|
||||
@@ -141,11 +140,10 @@ It's now necessary to tranfer the following files to your ==other== nodes, so th
|
||||
| `/etc/ceph/ceph.client.admin.keyring` | `/etc/ceph/ceph.client.admin.keyring` |
|
||||
| `/etc/ceph/ceph.pub` | `/root/.ssh/authorized_keys` (append to anything existing) |
|
||||
|
||||
|
||||
Back on the ==master== node, run `ceph orch host add <node-name>` once for each other node you want to join to the cluster. You can validate the results by running `ceph orch host ls`
|
||||
|
||||
!!! question "Should we be concerned about giving cephadm using root access over SSH?"
|
||||
Not really. Docker is inherently insecure at the host-level anyway (*think what would happen if you launched a global-mode stack with a malicious container image which mounted `/root/.ssh`*), so worrying about cephadm seems a little barn-door-after-horses-bolted. If you take host-level security seriously, consider switching to [Kubernetes](/kubernetes/) :)
|
||||
Not really. Docker is inherently insecure at the host-level anyway (*think what would happen if you launched a global-mode stack with a malicious container image which mounted `/root/.ssh`*), so worrying about cephadm seems a little barn-door-after-horses-bolted. If you take host-level security seriously, consider switching to [Kubernetes](/kubernetes/) :)
|
||||
|
||||
### Add OSDs
|
||||
|
||||
@@ -161,7 +159,7 @@ You can watch the progress by running `ceph fs ls` (to see the fs is configured)
|
||||
|
||||
On ==every== node, create a mountpoint for the data, by running ```mkdir /var/data```, add an entry to fstab to ensure the volume is auto-mounted on boot, and ensure the volume is actually _mounted_ if there's a network / boot delay getting access to the gluster volume:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data
|
||||
|
||||
MYNODES="<node1>,<node2>,<node3>" # Add your own nodes here, comma-delimited
|
||||
@@ -184,14 +182,13 @@ mount -a
|
||||
mount -a
|
||||
```
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Sprinkle with tools
|
||||
|
||||
Although it's possible to use `cephadm shell` to exec into a container with the necessary ceph tools, it's more convenient to use the native CLI tools. To this end, on each node, run the following, which will install the appropriate apt repository, and install the latest ceph CLI tools:
|
||||
|
||||
```
|
||||
```bash
|
||||
curl -L https://download.ceph.com/keys/release.asc | sudo apt-key add -
|
||||
cephadm add-repo --release octopus
|
||||
cephadm install ceph-common
|
||||
@@ -199,9 +196,9 @@ cephadm install ceph-common
|
||||
|
||||
### Drool over dashboard
|
||||
|
||||
Ceph now includes a comprehensive dashboard, provided by the mgr daemon. The dashboard will be accessible at https://[IP of your ceph master node]:8443, but you'll need to run `ceph dashboard ac-user-create <username> <password> administrator` first, to create an administrator account:
|
||||
Ceph now includes a comprehensive dashboard, provided by the mgr daemon. The dashboard will be accessible at `https://[IP of your ceph master node]:8443`, but you'll need to run `ceph dashboard ac-user-create <username> <password> administrator` first, to create an administrator account:
|
||||
|
||||
```
|
||||
```bash
|
||||
root@raphael:~# ceph dashboard ac-user-create batman supermansucks administrator
|
||||
{"username": "batman", "password": "$2b$12$3HkjY85mav.dq3HHAZiWP.KkMiuoV2TURZFH.6WFfo/BPZCT/0gr.", "roles": ["administrator"], "name": null, "email": null, "lastUpdate": 1590372281, "enabled": true, "pwdExpirationDate": null, "pwdUpdateRequired": false}
|
||||
root@raphael:~#
|
||||
@@ -223,11 +220,7 @@ What have we achieved?
|
||||
Here's a screencast of the playbook in action. I sped up the boring parts, it actually takes ==5 min== (*you can tell by the timestamps on the prompt*):
|
||||
|
||||

|
||||
[patreon]: https://www.patreon.com/bePatron?u=6982506
|
||||
[github_sponsor]: https://github.com/sponsors/funkypenguin
|
||||
[patreon]: <https://www.patreon.com/bePatron?u=6982506>
|
||||
[github_sponsor]: <https://github.com/sponsors/funkypenguin>
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -32,7 +32,7 @@ On each host, run a variation following to create your bricks, adjusted for the
|
||||
|
||||
!!! note "The example below assumes /dev/vdb is dedicated to the gluster volume"
|
||||
|
||||
```
|
||||
```bash
|
||||
(
|
||||
echo o # Create a new empty DOS partition table
|
||||
echo n # Add a new partition
|
||||
@@ -60,7 +60,7 @@ Atomic doesn't include the Gluster server components. This means we'll have to
|
||||
|
||||
Run the following on each host:
|
||||
|
||||
````
|
||||
````bash
|
||||
docker run \
|
||||
-h glusterfs-server \
|
||||
-v /etc/glusterfs:/etc/glusterfs:z \
|
||||
@@ -82,7 +82,7 @@ From the node, run `gluster peer probe <other host>`.
|
||||
|
||||
Example output:
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@glusterfs-server /]# gluster peer probe ds1
|
||||
peer probe: success.
|
||||
[root@glusterfs-server /]#
|
||||
@@ -92,7 +92,7 @@ Run ```gluster peer status``` on both nodes to confirm that they're properly con
|
||||
|
||||
Example output:
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@glusterfs-server /]# gluster peer status
|
||||
Number of Peers: 1
|
||||
|
||||
@@ -108,7 +108,7 @@ Now we create a *replicated volume* out of our individual "bricks".
|
||||
|
||||
Create the gluster volume by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
gluster volume create gv0 replica 2 \
|
||||
server1:/var/no-direct-write-here/brick1 \
|
||||
server2:/var/no-direct-write-here/brick1
|
||||
@@ -116,7 +116,7 @@ gluster volume create gv0 replica 2 \
|
||||
|
||||
Example output:
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@glusterfs-server /]# gluster volume create gv0 replica 2 ds1:/var/no-direct-write-here/brick1/gv0 ds3:/var/no-direct-write-here/brick1/gv0
|
||||
volume create: gv0: success: please start the volume to access data
|
||||
[root@glusterfs-server /]#
|
||||
@@ -124,7 +124,7 @@ volume create: gv0: success: please start the volume to access data
|
||||
|
||||
Start the volume by running ```gluster volume start gv0```
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@glusterfs-server /]# gluster volume start gv0
|
||||
volume start: gv0: success
|
||||
[root@glusterfs-server /]#
|
||||
@@ -138,7 +138,7 @@ From one other host, run ```docker exec -it glusterfs-server bash``` to shell in
|
||||
|
||||
On the host (i.e., outside of the container - type ```exit``` if you're still shelled in), create a mountpoint for the data, by running ```mkdir /var/data```, add an entry to fstab to ensure the volume is auto-mounted on boot, and ensure the volume is actually _mounted_ if there's a network / boot delay getting access to the gluster volume:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data
|
||||
MYHOST=`hostname -s`
|
||||
echo '' >> /etc/fstab >> /etc/fstab
|
||||
@@ -149,7 +149,7 @@ mount -a
|
||||
|
||||
For some reason, my nodes won't auto-mount this volume on boot. I even tried the trickery below, but they stubbornly refuse to automount:
|
||||
|
||||
```
|
||||
```bash
|
||||
echo -e "\n\n# Give GlusterFS 10s to start before \
|
||||
mounting\nsleep 10s && mount -a" >> /etc/rc.local
|
||||
systemctl enable rc-local.service
|
||||
@@ -168,4 +168,4 @@ After completing the above, you should have:
|
||||
1. Migration of shared storage from GlusterFS to Ceph ()[#2](https://gitlab.funkypenguin.co.nz/funkypenguin/geeks-cookbook/issues/2))
|
||||
2. Correct the fact that volumes don't automount on boot ([#3](https://gitlab.funkypenguin.co.nz/funkypenguin/geeks-cookbook/issues/3))
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -29,11 +29,11 @@ Under normal OIDC auth, you have to tell your auth provider which URLs it may re
|
||||
|
||||
[@thomaseddon's traefik-forward-auth](https://github.com/thomseddon/traefik-forward-auth) includes an ingenious mechanism to simulate an "_auth host_" in your OIDC authentication, so that you can protect an unlimited amount of DNS names (_with a common domain suffix_), without having to manually maintain a list.
|
||||
|
||||
#### How does it work?
|
||||
### How does it work?
|
||||
|
||||
Say you're protecting **radarr.example.com**. When you first browse to **https://radarr.example.com**, Traefik forwards your session to traefik-forward-auth, to be authenticated. Traefik-forward-auth redirects you to your OIDC provider's login (_KeyCloak, in this case_), but instructs the OIDC provider to redirect a successfully authenticated session **back** to **https://auth.example.com/_oauth**, rather than to **https://radarr.example.com/_oauth**.
|
||||
Say you're protecting **radarr.example.com**. When you first browse to **<https://radarr.example.com>**, Traefik forwards your session to traefik-forward-auth, to be authenticated. Traefik-forward-auth redirects you to your OIDC provider's login (_KeyCloak, in this case_), but instructs the OIDC provider to redirect a successfully authenticated session **back** to **<https://auth.example.com/_oauth>**, rather than to **<https://radarr.example.com/_oauth>**.
|
||||
|
||||
When you successfully authenticate against the OIDC provider, you are redirected to the "_redirect_uri_" of https://auth.example.com. Again, your request hits Traefik, which forwards the session to traefik-forward-auth, which **knows** that you've just been authenticated (_cookies have a role to play here_). Traefik-forward-auth also knows the URL of your **original** request (_thanks to the X-Forwarded-Whatever header_). Traefik-forward-auth redirects you to your original destination, and everybody is happy.
|
||||
When you successfully authenticate against the OIDC provider, you are redirected to the "_redirect_uri_" of <https://auth.example.com>. Again, your request hits Traefik, which forwards the session to traefik-forward-auth, which **knows** that you've just been authenticated (_cookies have a role to play here_). Traefik-forward-auth also knows the URL of your **original** request (_thanks to the X-Forwarded-Whatever header_). Traefik-forward-auth redirects you to your original destination, and everybody is happy.
|
||||
|
||||
This clever workaround only works under 2 conditions:
|
||||
|
||||
@@ -50,4 +50,4 @@ Traefik Forward Auth needs to authenticate an incoming user against a provider.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
[^1]: Authhost mode is specifically handy for Google authentication, since Google doesn't permit wildcard redirect_uris, like [KeyCloak][keycloak] does.
|
||||
[^1]: Authhost mode is specifically handy for Google authentication, since Google doesn't permit wildcard redirect_uris, like [KeyCloak][keycloak] does.
|
||||
|
||||
@@ -49,7 +49,7 @@ staticPasswords:
|
||||
|
||||
Create `/var/data/config/traefik-forward-auth/traefik-forward-auth.env` as follows:
|
||||
|
||||
```
|
||||
```bash
|
||||
DEFAULT_PROVIDER: oidc
|
||||
PROVIDERS_OIDC_CLIENT_ID: foo # This is the staticClients.id value in config.yml above
|
||||
PROVIDERS_OIDC_CLIENT_SECRET: bar # This is the staticClients.secret value in config.yml above
|
||||
@@ -176,7 +176,7 @@ Once you redeploy traefik-forward-auth with the above, it **should** use dex as
|
||||
|
||||
### Test
|
||||
|
||||
Browse to https://whoami.example.com (_obviously, customized for your domain and having created a DNS record_), and all going according to plan, you'll be redirected to a CoreOS Dex login. Once successfully logged in, you'll be directed to the basic whoami page :thumbsup:
|
||||
Browse to <https://whoami.example.com> (_obviously, customized for your domain and having created a DNS record_), and all going according to plan, you'll be redirected to a CoreOS Dex login. Once successfully logged in, you'll be directed to the basic whoami page :thumbsup:
|
||||
|
||||
### Protect services
|
||||
|
||||
|
||||
@@ -12,9 +12,9 @@ This recipe will illustrate how to point Traefik Forward Auth to Google, confirm
|
||||
|
||||
#### TL;DR
|
||||
|
||||
Log into https://console.developers.google.com/, create a new project then search for and select "**Credentials**" in the search bar.
|
||||
Log into <https://console.developers.google.com/>, create a new project then search for and select "**Credentials**" in the search bar.
|
||||
|
||||
Fill out the "OAuth Consent Screen" tab, and then click, "**Create Credentials**" > "**OAuth client ID**". Select "**Web Application**", fill in the name of your app, skip "**Authorized JavaScript origins**" and fill "**Authorized redirect URIs**" with either all the domains you will allow authentication from, appended with the url-path (*e.g. https://radarr.example.com/_oauth, https://radarr.example.com/_oauth, etc*), or if you don't like frustration, use a "auth host" URL instead, like "*https://auth.example.com/_oauth*" (*see below for details*)
|
||||
Fill out the "OAuth Consent Screen" tab, and then click, "**Create Credentials**" > "**OAuth client ID**". Select "**Web Application**", fill in the name of your app, skip "**Authorized JavaScript origins**" and fill "**Authorized redirect URIs**" with either all the domains you will allow authentication from, appended with the url-path (*e.g. <https://radarr.example.com/_oauth>, <https://radarr.example.com/_oauth>, etc*), or if you don't like frustration, use a "auth host" URL instead, like "*<https://auth.example.com/_oauth>*" (*see below for details*)
|
||||
|
||||
#### Monkey see, monkey do 🙈
|
||||
|
||||
@@ -27,7 +27,7 @@ Here's a [screencast I recorded](https://static.funkypenguin.co.nz/2021/screenca
|
||||
|
||||
Create `/var/data/config/traefik-forward-auth/traefik-forward-auth.env` as follows:
|
||||
|
||||
```
|
||||
```bash
|
||||
PROVIDERS_GOOGLE_CLIENT_ID=<your client id>
|
||||
PROVIDERS_GOOGLE_CLIENT_SECRET=<your client secret>
|
||||
SECRET=<a random string, make it up>
|
||||
@@ -41,7 +41,7 @@ WHITELIST=you@yourdomain.com, me@mydomain.com
|
||||
|
||||
Create `/var/data/config/traefik-forward-auth/traefik-forward-auth.yml` as follows:
|
||||
|
||||
```
|
||||
```yaml
|
||||
traefik-forward-auth:
|
||||
image: thomseddon/traefik-forward-auth:2.1.0
|
||||
env_file: /var/data/config/traefik-forward-auth/traefik-forward-auth.env
|
||||
@@ -77,7 +77,7 @@ Create `/var/data/config/traefik-forward-auth/traefik-forward-auth.yml` as follo
|
||||
|
||||
If you're not confident that forward authentication is working, add a simple "whoami" test container to the above .yml, to help debug traefik forward auth, before attempting to add it to a more complex container.
|
||||
|
||||
```
|
||||
```yaml
|
||||
# This simply validates that traefik forward authentication is working
|
||||
whoami:
|
||||
image: containous/whoami
|
||||
@@ -114,7 +114,7 @@ Deploy traefik-forward-auth with ```docker stack deploy traefik-forward-auth -c
|
||||
|
||||
### Test
|
||||
|
||||
Browse to https://whoami.example.com (*obviously, customized for your domain and having created a DNS record*), and all going according to plan, you should be redirected to a Google login. Once successfully logged in, you'll be directed to the basic whoami page.
|
||||
Browse to <https://whoami.example.com> (*obviously, customized for your domain and having created a DNS record*), and all going according to plan, you should be redirected to a Google login. Once successfully logged in, you'll be directed to the basic whoami page.
|
||||
|
||||
## Summary
|
||||
|
||||
@@ -127,4 +127,4 @@ What have we achieved? By adding an additional three simple labels to any servic
|
||||
|
||||
[^1]: Be sure to populate `WHITELIST` in `traefik-forward-auth.env`, else you'll happily be granting **any** authenticated Google account access to your services!
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -10,7 +10,7 @@ While the [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/) recipe
|
||||
|
||||
Create `/var/data/config/traefik/traefik-forward-auth.env` as follows (_change "master" if you created a different realm_):
|
||||
|
||||
```
|
||||
```bash
|
||||
CLIENT_ID=<your keycloak client name>
|
||||
CLIENT_SECRET=<your keycloak client secret>
|
||||
OIDC_ISSUER=https://<your keycloak URL>/auth/realms/master
|
||||
@@ -23,8 +23,8 @@ COOKIE_DOMAIN=<the root FQDN of your domain>
|
||||
|
||||
This is a small container, you can simply add the following content to the existing `traefik-app.yml` deployed in the previous [Traefik](/ha-docker-swarm/traefik/) recipe:
|
||||
|
||||
```
|
||||
traefik-forward-auth:
|
||||
```bash
|
||||
traefik-forward-auth:
|
||||
image: funkypenguin/traefik-forward-auth
|
||||
env_file: /var/data/config/traefik/traefik-forward-auth.env
|
||||
networks:
|
||||
@@ -39,8 +39,8 @@ This is a small container, you can simply add the following content to the exist
|
||||
|
||||
If you're not confident that forward authentication is working, add a simple "whoami" test container, to help debug traefik forward auth, before attempting to add it to a more complex container.
|
||||
|
||||
```
|
||||
# This simply validates that traefik forward authentication is working
|
||||
```bash
|
||||
# This simply validates that traefik forward authentication is working
|
||||
whoami:
|
||||
image: containous/whoami
|
||||
networks:
|
||||
@@ -64,13 +64,13 @@ Redeploy traefik with `docker stack deploy traefik-app -c /var/data/traefik/trae
|
||||
|
||||
### Test
|
||||
|
||||
Browse to https://whoami.example.com (_obviously, customized for your domain and having created a DNS record_), and all going according to plan, you'll be redirected to a KeyCloak login. Once successfully logged in, you'll be directed to the basic whoami page.
|
||||
Browse to <https://whoami.example.com> (_obviously, customized for your domain and having created a DNS record_), and all going according to plan, you'll be redirected to a KeyCloak login. Once successfully logged in, you'll be directed to the basic whoami page.
|
||||
|
||||
### Protect services
|
||||
|
||||
To protect any other service, ensure the service itself is exposed by Traefik (_if you were previously using an oauth_proxy for this, you may have to migrate some labels from the oauth_proxy serivce to the service itself_). Add the following 3 labels:
|
||||
|
||||
```
|
||||
```yaml
|
||||
- traefik.frontend.auth.forward.address=http://traefik-forward-auth:4181
|
||||
- traefik.frontend.auth.forward.authResponseHeaders=X-Forwarded-User
|
||||
- traefik.frontend.auth.forward.trustForwardHeader=true
|
||||
@@ -89,4 +89,4 @@ What have we achieved? By adding an additional three simple labels to any servic
|
||||
|
||||
[^1]: KeyCloak is very powerful. You can add 2FA and all other clever things outside of the scope of this simple recipe ;)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -36,7 +36,7 @@ While it's possible to configure traefik via docker command arguments, I prefer
|
||||
|
||||
Create `/var/data/traefikv2/traefik.toml` as follows:
|
||||
|
||||
```
|
||||
```bash
|
||||
[global]
|
||||
checkNewVersion = true
|
||||
|
||||
@@ -87,7 +87,7 @@ Create `/var/data/traefikv2/traefik.toml` as follows:
|
||||
|
||||
Create `/var/data/config/traefik/traefik.yml` as follows:
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: "3.2"
|
||||
|
||||
# What is this?
|
||||
@@ -116,7 +116,7 @@ networks:
|
||||
|
||||
Create `/var/data/config/traefikv2/traefikv2.env` with the environment variables required by the provider you chose in the LetsEncrypt DNS Challenge section of `traefik.toml`. Full configuration options can be found in the [Traefik documentation](https://doc.traefik.io/traefik/https/acme/#providers). Route53 and CloudFlare examples are below.
|
||||
|
||||
```
|
||||
```bash
|
||||
# Route53 example
|
||||
AWS_ACCESS_KEY_ID=<your-aws-key>
|
||||
AWS_SECRET_ACCESS_KEY=<your-aws-secret>
|
||||
@@ -185,7 +185,7 @@ networks:
|
||||
|
||||
Docker won't start a service with a bind-mount to a non-existent file, so prepare an empty acme.json and traefik.log (_with the appropriate permissions_) by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
touch /var/data/traefikv2/acme.json
|
||||
touch /var/data/traefikv2/traefik.log
|
||||
chmod 600 /var/data/traefikv2/acme.json
|
||||
@@ -205,7 +205,7 @@ Likewise with the log file.
|
||||
|
||||
First, launch the traefik stack, which will do nothing other than create an overlay network by running `docker stack deploy traefik -c /var/data/config/traefik/traefik.yml`
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@kvm ~]# docker stack deploy traefik -c /var/data/config/traefik/traefik.yml
|
||||
Creating network traefik_public
|
||||
Creating service traefik_scratch
|
||||
@@ -214,7 +214,7 @@ Creating service traefik_scratch
|
||||
|
||||
Now deploy the traefik application itself (*which will attach to the overlay network*) by running `docker stack deploy traefikv2 -c /var/data/config/traefikv2/traefikv2.yml`
|
||||
|
||||
```
|
||||
```bash
|
||||
[root@kvm ~]# docker stack deploy traefikv2 -c /var/data/config/traefikv2/traefikv2.yml
|
||||
Creating service traefikv2_traefikv2
|
||||
[root@kvm ~]#
|
||||
@@ -222,7 +222,7 @@ Creating service traefikv2_traefikv2
|
||||
|
||||
Confirm traefik is running with `docker stack ps traefikv2`:
|
||||
|
||||
```
|
||||
```bash
|
||||
root@raphael:~# docker stack ps traefikv2
|
||||
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
|
||||
lmvqcfhap08o traefikv2_app.dz178s1aahv16bapzqcnzc03p traefik:v2.4 donatello Running Running 2 minutes ago *:443->443/tcp,*:80->80/tcp
|
||||
@@ -231,11 +231,11 @@ root@raphael:~#
|
||||
|
||||
### Check Traefik Dashboard
|
||||
|
||||
You should now be able to access[^1] your traefik instance on **https://traefik.<your domain\>** (*if your LetsEncrypt certificate is working*), or **http://<node IP\>:8080** (*if it's not*)- It'll look a little lonely currently (*below*), but we'll populate it as we add recipes :grin:
|
||||
You should now be able to access[^1] your traefik instance on `https://traefik.<your domain\>` (*if your LetsEncrypt certificate is working*), or `http://<node IP\>:8080` (*if it's not*)- It'll look a little lonely currently (*below*), but we'll populate it as we add recipes :grin:
|
||||
|
||||

|
||||
|
||||
### Summary
|
||||
### Summary
|
||||
|
||||
!!! summary
|
||||
We've achieved:
|
||||
@@ -246,4 +246,4 @@ You should now be able to access[^1] your traefik instance on **https://traefik.
|
||||
|
||||
[^1]: Did you notice how no authentication was required to view the Traefik dashboard? Eek! We'll tackle that in the next section, regarding [Traefik Forward Authentication](/ha-docker-swarm/traefik-forward-auth/)!
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 128 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 310 KiB |
+3
-7
@@ -8,7 +8,7 @@ hide:
|
||||
|
||||
## What is this?
|
||||
|
||||
Funky Penguin's "**[Geek Cookbook](https://geek-cookbook.funkypenguin.co.nz)**" is a collection of how-to guides for establishing your own container-based self-hosting platform, using either [Docker Swarm](/ha-docker-swarm/design/) or [Kubernetes](/kubernetes/).
|
||||
Funky Penguin's "**[Geek Cookbook](https://geek-cookbook.funkypenguin.co.nz)**" is a collection of how-to guides for establishing your own container-based self-hosting platform, using either [Docker Swarm](/ha-docker-swarm/design/) or [Kubernetes](/kubernetes/).
|
||||
|
||||
[Dive into Docker Swarm](/ha-docker-swarm/design/){: .md-button .md-button--primary}
|
||||
[Kick it with Kubernetes](/kubernetes/){: .md-button}
|
||||
@@ -44,7 +44,6 @@ So if you're familiar enough with the concepts above, and you've done self-hosti
|
||||
|
||||
:wave: Hi, I'm [David](https://www.funkypenguin.co.nz/about/)
|
||||
|
||||
|
||||
## What have you done for me lately? (CHANGELOG)
|
||||
|
||||
Check out recent change at [CHANGELOG](/CHANGELOG/)
|
||||
@@ -59,7 +58,6 @@ I want your [support](https://github.com/sponsors/funkypenguin), either in the [
|
||||
* Tweet me up, I'm [@funkypenguin](https://twitter.com/funkypenguin)! 🐦
|
||||
* [Contact me](https://www.funkypenguin.co.nz/contact/) by a variety of channels
|
||||
|
||||
|
||||
### [Sponsor](https://github.com/sponsors/funkypenguin) / [Patronize](https://www.patreon.com/bePatron?u=6982506) me ❤️
|
||||
|
||||
The best way to support this work is to become a [GitHub Sponsor](https://github.com/sponsors/funkypenguin) / [Patreon patron](https://www.patreon.com/bePatron?u=6982506). You get:
|
||||
@@ -77,7 +75,6 @@ Impulsively **[click here (NOW quick do it!)](https://github.com/sponsors/funkyp
|
||||
|
||||
Need some Cloud / Microservices / DevOps / Infrastructure design work done? I'm a full-time [AWS](https://www.youracclaim.com/badges/a0c4a196-55ab-4472-b46b-b610b44dc00f/public_url) / [CNCF](https://www.youracclaim.com/badges/cd307d51-544b-4bc6-97b0-9015e40df40d/public_url)-[certified](https://www.youracclaim.com/badges/9ed9280a-fb92-46ca-b307-8f74a2cccf1d/public_url) [cloud/architecture consultant](https://www.funkypenguin.co.nz/about/), I've been doing (*and loving!*) this for 20+ years, and it's my bread and butter! :bread: :fork_and_knife: [Get in touch](https://www.funkypenguin.co.nz/contact/), and let's talk business!
|
||||
|
||||
|
||||
!!! quote "He unblocked me on all the technical hurdles to launching my SaaS in GKE!"
|
||||
|
||||
By the time I had enlisted Funky Penguin's help, I'd architected myself into a bit of a nightmare with Kubernetes. I knew what I wanted to achieve, but I'd made a mess of it. Funky Penguin (David) was able to jump right in and offer a vital second-think on everything I'd done, pointing out where things could be simplified and streamlined, and better alternatives.
|
||||
@@ -92,7 +89,7 @@ Need some Cloud / Microservices / DevOps / Infrastructure design work done? I'm
|
||||
|
||||
### Buy my book 📖
|
||||
|
||||
I'm publishing the Geek Cookbook as a formal eBook (*PDF, mobi, epub*), on Leanpub (https://leanpub.com/geek-cookbook). Check it out!
|
||||
I'm publishing the Geek Cookbook as a formal eBook (*PDF, mobi, epub*), on Leanpub (<https://leanpub.com/geek-cookbook>). Check it out!
|
||||
|
||||
### Sponsored Projects
|
||||
|
||||
@@ -100,7 +97,7 @@ I'm supported and motivated by [GitHub Sponsors](https://github.com/sponsors/fun
|
||||
|
||||
I regularly donate to / sponsor the following projects. **Join me** in supporting these geeks, and encouraging them to continue building the ingredients for your favourite recipes!
|
||||
|
||||
| Project | Donate via..
|
||||
| Project | Donate via..
|
||||
| ------------- |-------------|
|
||||
| [Komga](/recipes/komga/) | [GitHub Sponsors](https://github.com/sponsors/gotson)
|
||||
| [Material for MKDocs](https://squidfunk.github.io/mkdocs-material/) | [GitHub Sponsors](https://github.com/sponsors/squidfunk)
|
||||
@@ -108,4 +105,3 @@ I regularly donate to / sponsor the following projects. **Join me** in supportin
|
||||
| [LinuxServer.io](https://www.linuxserver.io) | [PayPal](https://www.linuxserver.io/donate)
|
||||
| [WidgetBot's Discord Widget](https://widgetbot.io/) | [Patreon](https://www.patreon.com/widgetbot/overview)
|
||||
| [Carl-bot](https://carl.gg/) | [Patreon](https://www.patreon.com/carlbot)
|
||||
|
||||
|
||||
@@ -42,7 +42,8 @@ DigitalOcean will provide you with a "kubeconfig" file to use to access your clu
|
||||
Save your kubeconfig file somewhere, and test it our by running ```kubectl --kubeconfig=<PATH TO KUBECONFIG> get nodes```
|
||||
|
||||
Example output:
|
||||
```
|
||||
|
||||
```bash
|
||||
[davidy:~/Downloads] 130 % kubectl --kubeconfig=penguins-are-the-sexiest-geeks-kubeconfig.yaml get nodes
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
festive-merkle-8n9e Ready <none> 20s v1.13.1
|
||||
@@ -51,7 +52,7 @@ festive-merkle-8n9e Ready <none> 20s v1.13.1
|
||||
|
||||
In the example above, my nodes were being deployed. Repeat the command to see your nodes spring into existence:
|
||||
|
||||
```
|
||||
```bash
|
||||
[davidy:~/Downloads] % kubectl --kubeconfig=penguins-are-the-sexiest-geeks-kubeconfig.yaml get nodes
|
||||
NAME STATUS ROLES AGE VERSION
|
||||
festive-merkle-8n96 Ready <none> 6s v1.13.1
|
||||
@@ -80,7 +81,6 @@ Still with me? Good. Move on to creating your own external load balancer..
|
||||
* [Helm](/kubernetes/helm/) - Uber-recipes from fellow geeks
|
||||
* [Traefik](/kubernetes/traefik/) - Traefik Ingress via Helm
|
||||
|
||||
|
||||
[^1]: Ok, yes, there's not much you can do with your cluster _yet_. But stay tuned, more Kubernetes fun to come!
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -15,21 +15,21 @@ _Unlike_ the Docker Swarm design, the Kubernetes design is:
|
||||
|
||||
## Design Decisions
|
||||
|
||||
**The design and recipes are provider-agnostic**
|
||||
### The design and recipes are provider-agnostic**
|
||||
|
||||
This means that:
|
||||
|
||||
- The design should work on GKE, AWS, DigitalOcean, Azure, or even MicroK8s
|
||||
- Custom service elements specific to individual providers are avoided
|
||||
|
||||
**The simplest solution to achieve the desired result will be preferred**
|
||||
### The simplest solution to achieve the desired result will be preferred**
|
||||
|
||||
This means that:
|
||||
|
||||
- Persistent volumes from the cloud provider are used for all persistent storage
|
||||
- We'll do things the "_Kubernetes way_", i.e., using secrets and configmaps, rather than trying to engineer around the Kubernetes basic building blocks.
|
||||
|
||||
**Insofar as possible, the format of recipes will align with Docker Swarm**
|
||||
### Insofar as possible, the format of recipes will align with Docker Swarm**
|
||||
|
||||
This means that:
|
||||
|
||||
|
||||
@@ -310,4 +310,4 @@ Feel free to talk to today's chef in the discord, or see one of his many other l
|
||||
The links above are just redirect links incase anything ever changes, and it has analytics too
|
||||
-->
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -31,7 +31,6 @@ To rapidly get Helm up and running, start with the [Quick Start Guide](https://h
|
||||
See the [installation guide](https://helm.sh/docs/intro/install/) for more options,
|
||||
including installing pre-releases.
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Initialise Helm
|
||||
@@ -44,15 +43,14 @@ That's it - not very exciting I know, but we'll need helm for the next and final
|
||||
|
||||
Still with me? Good. Move on to understanding Helm charts...
|
||||
|
||||
* [Start](/kubernetes/) - Why Kubernetes?
|
||||
* [Design](/kubernetes/design/) - How does it fit together?
|
||||
* [Cluster](/kubernetes/cluster/) - Setup a basic cluster
|
||||
* [Load Balancer](/kubernetes/loadbalancer/) Setup inbound access
|
||||
* [Snapshots](/kubernetes/snapshots/) - Automatically backup your persistent data
|
||||
* Helm (this page) - Uber-recipes from fellow geeks
|
||||
* [Traefik](/kubernetes/traefik/) - Traefik Ingress via Helm
|
||||
- [Start](/kubernetes/) - Why Kubernetes?
|
||||
- [Design](/kubernetes/design/) - How does it fit together?
|
||||
- [Cluster](/kubernetes/cluster/) - Setup a basic cluster
|
||||
- [Load Balancer](/kubernetes/loadbalancer/) Setup inbound access
|
||||
- [Snapshots](/kubernetes/snapshots/) - Automatically backup your persistent data
|
||||
- Helm (this page) - Uber-recipes from fellow geeks
|
||||
- [Traefik](/kubernetes/traefik/) - Traefik Ingress via Helm
|
||||
|
||||
|
||||
[^1]: Of course, you can have lots of fun deploying all sorts of things via Helm. Check out https://artifacthub.io for some examples.
|
||||
[^1]: Of course, you can have lots of fun deploying all sorts of things via Helm. Check out <https://artifacthub.io> for some examples.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
|
||||
My first introduction to Kubernetes was a children's story:
|
||||
|
||||
<!-- markdownlint-disable MD033 -->
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/4ht22ReBjno" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
|
||||
|
||||
## Wait, what?
|
||||
@@ -44,7 +45,7 @@ Let's talk some definitions. Kubernetes.io provides a [glossary](https://kuberne
|
||||
|
||||
## Mm.. maaaaybe, how do I start?
|
||||
|
||||
If you're like me, and you learn by doing, either play with the examples at https://labs.play-with-k8s.com/, or jump right in by setting up a Google Cloud trial (_you get \$300 credit for 12 months_), or a small cluster on [Digital Ocean](/kubernetes/cluster/).
|
||||
If you're like me, and you learn by doing, either play with the examples at <https://labs.play-with-k8s.com/>, or jump right in by setting up a Google Cloud trial (_you get \$300 credit for 12 months_), or a small cluster on [Digital Ocean](/kubernetes/cluster/).
|
||||
|
||||
If you're the learn-by-watching type, just search for "Kubernetes introduction video". There's a **lot** of great content available.
|
||||
|
||||
|
||||
@@ -31,14 +31,14 @@ We **could** run our webhook as a simple HTTP listener, but really, in a world w
|
||||
|
||||
In my case, since I use CloudFlare, I create /etc/webhook/letsencrypt/cloudflare.ini:
|
||||
|
||||
```
|
||||
```ini
|
||||
dns_cloudflare_email=davidy@funkypenguin.co.nz
|
||||
dns_cloudflare_api_key=supersekritnevergonnatellyou
|
||||
```
|
||||
|
||||
I request my cert by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
cd /etc/webhook/
|
||||
docker run -ti --rm -v "$(pwd)"/letsencrypt:/etc/letsencrypt certbot/dns-cloudflare --preferred-challenges dns certonly --dns-cloudflare --dns-cloudflare-credentials /etc/letsencrypt/cloudflare.ini -d ''*.funkypenguin.co.nz'
|
||||
```
|
||||
@@ -48,7 +48,7 @@ Why use a wildcard cert? So my enemies can't examine my certs to enumerate my va
|
||||
|
||||
I add the following as a cron command to renew my certs every day:
|
||||
|
||||
```
|
||||
```bash
|
||||
cd /etc/webhook && docker run -ti --rm -v "$(pwd)"/letsencrypt:/etc/letsencrypt certbot/dns-cloudflare renew --dns-cloudflare --dns-cloudflare-credentials /etc/letsencrypt/cloudflare.ini
|
||||
```
|
||||
|
||||
@@ -56,13 +56,13 @@ Once you've confirmed you've got a valid LetsEncrypt certificate stored in `/etc
|
||||
|
||||
### Install webhook
|
||||
|
||||
We're going to use https://github.com/adnanh/webhook to run our webhook. On some distributions (_❤️ ya, Debian!_), webhook and its associated systemd config can be installed by running `apt-get install webhook`.
|
||||
We're going to use <https://github.com/adnanh/webhook> to run our webhook. On some distributions (_❤️ ya, Debian!_), webhook and its associated systemd config can be installed by running `apt-get install webhook`.
|
||||
|
||||
### Create webhook config
|
||||
|
||||
We'll create a single webhook, by creating `/etc/webhook/hooks.json` as follows. Choose a nice secure random string for your MY_TOKEN value!
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /etc/webhook
|
||||
export MY_TOKEN=ilovecheese
|
||||
echo << EOF > /etc/webhook/hooks.json
|
||||
@@ -100,8 +100,8 @@ echo << EOF > /etc/webhook/hooks.json
|
||||
{
|
||||
"type": "value",
|
||||
"value": "$MY_TOKEN",
|
||||
"parameter":
|
||||
{
|
||||
"parameter":
|
||||
{
|
||||
"source": "header",
|
||||
"name": "X-Funkypenguin-Token"
|
||||
}
|
||||
@@ -122,7 +122,7 @@ This section is particular to Debian Stretch and its webhook package. If you're
|
||||
|
||||
Since we want to force webhook to run in secure mode (_no point having a token if it can be extracted from a simple packet capture!_) I ran `systemctl edit webhook`, and pasted in the following:
|
||||
|
||||
```
|
||||
```bash
|
||||
[Service]
|
||||
# Override the default (non-secure) behaviour of webhook by passing our certificate details and custom hooks.json location
|
||||
ExecStart=
|
||||
@@ -135,7 +135,7 @@ Then I restarted webhook by running `systemctl enable webhook && systemctl resta
|
||||
|
||||
When successfully authenticated with our top-secret token, our webhook will execute a local script, defined as follows (_yes, you should create this file_):
|
||||
|
||||
```
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
NAME=$1
|
||||
@@ -153,9 +153,9 @@ fi
|
||||
|
||||
# Either add or remove a service based on $ACTION
|
||||
case $ACTION in
|
||||
add)
|
||||
# Create the portion of haproxy config
|
||||
cat << EOF > /etc/webhook/haproxy/$FRONTEND_PORT.inc
|
||||
add)
|
||||
# Create the portion of haproxy config
|
||||
cat << EOF > /etc/webhook/haproxy/$FRONTEND_PORT.inc
|
||||
### >> Used to run $NAME:${FRONTEND_PORT}
|
||||
frontend ${FRONTEND_PORT}_frontend
|
||||
bind *:$FRONTEND_PORT
|
||||
@@ -170,13 +170,13 @@ backend ${FRONTEND_PORT}_backend
|
||||
server s1 $DST_IP:$BACKEND_PORT
|
||||
### << Used to run $NAME:$FRONTEND_PORT
|
||||
EOF
|
||||
;;
|
||||
delete)
|
||||
rm /etc/webhook/haproxy/$FRONTEND_PORT.inc
|
||||
;;
|
||||
*)
|
||||
echo "Invalid action $ACTION"
|
||||
exit 2
|
||||
;;
|
||||
delete)
|
||||
rm /etc/webhook/haproxy/$FRONTEND_PORT.inc
|
||||
;;
|
||||
*)
|
||||
echo "Invalid action $ACTION"
|
||||
exit 2
|
||||
esac
|
||||
|
||||
# Concatenate all the haproxy configs into a single file
|
||||
@@ -188,8 +188,8 @@ haproxy -f /etc/webhook/haproxy/pre_validate.cfg -c
|
||||
# If validation was successful, only _then_ copy it over to /etc/haproxy/haproxy.cfg, and reload
|
||||
if [[ $? -gt 0 ]]
|
||||
then
|
||||
echo "HAProxy validation failed, not continuing"
|
||||
exit 2
|
||||
echo "HAProxy validation failed, not continuing"
|
||||
exit 2
|
||||
else
|
||||
# Remember what the original file looked like
|
||||
m1=$(md5sum "/etc/haproxy/haproxy.cfg")
|
||||
@@ -212,7 +212,7 @@ fi
|
||||
|
||||
Create `/etc/webhook/haproxy/global` and populate with something like the following. This will be the non-dynamically generated part of our HAProxy config:
|
||||
|
||||
```
|
||||
```ini
|
||||
global
|
||||
log /dev/log local0
|
||||
log /dev/log local1 notice
|
||||
@@ -256,7 +256,7 @@ defaults
|
||||
|
||||
### Take the bait!
|
||||
|
||||
Whew! We now have all the components of our automated load-balancing solution in place. Browse to your VM's FQDN at https://whatever.it.is:9000/hooks/update-haproxy, and you should see the text "_Hook rules were not satisfied_", with a valid SSL certificate (_You didn't send a token_).
|
||||
Whew! We now have all the components of our automated load-balancing solution in place. Browse to your VM's FQDN at <https://whatever.it.is:9000/hooks/update-haproxy>, and you should see the text "_Hook rules were not satisfied_", with a valid SSL certificate (_You didn't send a token_).
|
||||
|
||||
If you don't see the above, then check the following:
|
||||
|
||||
@@ -267,7 +267,7 @@ If you don't see the above, then check the following:
|
||||
|
||||
You'll see me use this design in any Kubernetes-based recipe which requires container-specific ports, like UniFi. Here's an excerpt of the .yml which defines the UniFi controller:
|
||||
|
||||
```
|
||||
```yaml
|
||||
<snip>
|
||||
spec:
|
||||
containers:
|
||||
@@ -305,7 +305,7 @@ The takeaways here are:
|
||||
|
||||
Here's what the webhook logs look like when the above is added to the UniFi deployment:
|
||||
|
||||
```
|
||||
```bash
|
||||
Feb 06 23:04:28 haproxy2 webhook[1433]: [webhook] 2019/02/06 23:04:28 Started POST /hooks/update-haproxy
|
||||
Feb 06 23:04:28 haproxy2 webhook[1433]: [webhook] 2019/02/06 23:04:28 update-haproxy got matched
|
||||
Feb 06 23:04:28 haproxy2 webhook[1433]: [webhook] 2019/02/06 23:04:28 update-haproxy hook triggered successfully
|
||||
|
||||
@@ -8,6 +8,7 @@ Now that we're playing in the deep end with Kubernetes, we'll need a Cloud-nativ
|
||||
|
||||
It bears repeating though - don't be like [Cameron](http://haltandcatchfire.wikia.com/wiki/Cameron_Howe). Backup your stuff.
|
||||
|
||||
<!-- markdownlint-disable MD033 -->
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/1UtFeMoqVHQ" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
|
||||
|
||||
This recipe employs a clever tool ([miracle2k/k8s-snapshots](https://github.com/miracle2k/k8s-snapshots)), running _inside_ your cluster, to trigger automated snapshots of your persistent volumes, using your cloud provider's APIs.
|
||||
@@ -33,10 +34,8 @@ If you're running GKE, run the following to create a RoleBinding, allowing your
|
||||
|
||||
If your cluster is RBAC-enabled (_it probably is_), you'll need to create a ClusterRole and ClusterRoleBinding to allow k8s_snapshots to see your PVs and friends:
|
||||
|
||||
````
|
||||
|
||||
````bash
|
||||
kubectl apply -f https://raw.githubusercontent.com/miracle2k/k8s-snapshots/master/rbac.yaml
|
||||
|
||||
```
|
||||
|
||||
## Serving
|
||||
@@ -45,7 +44,7 @@ kubectl apply -f https://raw.githubusercontent.com/miracle2k/k8s-snapshots/maste
|
||||
|
||||
Ready? Run the following to create a deployment in to the kube-system namespace:
|
||||
|
||||
```
|
||||
```bash
|
||||
|
||||
cat <<EOF | kubectl create -f -
|
||||
apiVersion: extensions/v1beta1
|
||||
@@ -74,39 +73,30 @@ k8s-snapshots relies on annotations to tell it how frequently to snapshot your P
|
||||
|
||||
From the k8s-snapshots README:
|
||||
|
||||
````
|
||||
|
||||
The generations are defined by a list of deltas formatted as ISO 8601 durations (this differs from tarsnapper). PT60S or PT1M means a minute, PT12H or P0.5D is half a day, P1W or P7D is a week. The number of backups in each generation is implied by it's and the parent generation's delta.
|
||||
|
||||
For example, given the deltas PT1H P1D P7D, the first generation will consist of 24 backups each one hour older than the previous (or the closest approximation possible given the available backups), the second generation of 7 backups each one day older than the previous, and backups older than 7 days will be discarded for good.
|
||||
|
||||
The most recent backup is always kept.
|
||||
|
||||
The first delta is the backup interval.
|
||||
|
||||
```
|
||||
> The generations are defined by a list of deltas formatted as ISO 8601 durations (this differs from tarsnapper). PT60S or PT1M means a minute, PT12H or P0.5D is half a day, P1W or P7D is a week. The number of backups in each generation is implied by it's and the parent generation's delta.
|
||||
>
|
||||
> For example, given the deltas PT1H P1D P7D, the first generation will consist of 24 backups each one hour older than the previous (or the closest approximation possible given the available backups), the second generation of 7 backups each one day older than the previous, and backups older than 7 days will be discarded for good.
|
||||
>
|
||||
> The most recent backup is always kept.
|
||||
>
|
||||
> The first delta is the backup interval.
|
||||
|
||||
To add the annotation to an existing PV, run something like this:
|
||||
|
||||
```
|
||||
|
||||
```bash
|
||||
kubectl patch pv pvc-01f74065-8fe9-11e6-abdd-42010af00148 -p \
|
||||
'{"metadata": {"annotations": {"backup.kubernetes.io/deltas": "P1D P30D P360D"}}}'
|
||||
|
||||
```
|
||||
|
||||
To add the annotation to a _new_ PV, add the following annotation to your **PVC**:
|
||||
|
||||
```
|
||||
|
||||
```yaml
|
||||
backup.kubernetes.io/deltas: PT1H P2D P30D P180D
|
||||
|
||||
```
|
||||
|
||||
Here's an example of the PVC for the UniFi recipe, which includes 7 daily snapshots of the PV:
|
||||
|
||||
```
|
||||
|
||||
```yaml
|
||||
kind: PersistentVolumeClaim
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
@@ -119,7 +109,6 @@ accessModes: - ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi
|
||||
|
||||
````
|
||||
|
||||
And here's what my snapshot list looks like after a few days:
|
||||
@@ -132,8 +121,7 @@ If you're running traditional compute instances with your cloud provider (I do t
|
||||
|
||||
To do so, first create a custom resource, ```SnapshotRule```:
|
||||
|
||||
````
|
||||
|
||||
````bash
|
||||
cat <<EOF | kubectl create -f -
|
||||
apiVersion: apiextensions.k8s.io/v1beta1
|
||||
kind: CustomResourceDefinition
|
||||
@@ -149,13 +137,11 @@ singular: snapshotrule
|
||||
kind: SnapshotRule
|
||||
shortNames: - sr
|
||||
EOF
|
||||
|
||||
````
|
||||
|
||||
Then identify the volume ID of your volume, and create an appropriate ```SnapshotRule```:
|
||||
|
||||
````
|
||||
|
||||
````bash
|
||||
cat <<EOF | kubectl apply -f -
|
||||
apiVersion: "k8s-snapshots.elsdoerfer.com/v1"
|
||||
kind: SnapshotRule
|
||||
|
||||
@@ -13,13 +13,13 @@ This recipe utilises the [traefik helm chart](https://github.com/helm/charts/tre
|
||||
|
||||
Clone the helm charts, by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
git clone https://github.com/helm/charts
|
||||
```
|
||||
|
||||
Change to stable/traefik:
|
||||
|
||||
```
|
||||
```bash
|
||||
cd charts/stable/traefik
|
||||
```
|
||||
|
||||
@@ -29,7 +29,7 @@ The beauty of the helm approach is that all the complexity of the Kubernetes ele
|
||||
|
||||
These are my values, you'll need to adjust for your own situation:
|
||||
|
||||
```
|
||||
```yaml
|
||||
imageTag: alpine
|
||||
serviceType: NodePort
|
||||
# yes, we're not listening on 80 or 443 because we don't want to pay for a loadbalancer IP to do this. I use poor-mans-k8s-lb instead
|
||||
@@ -101,7 +101,7 @@ Since we deployed Traefik using helm, we need to take a slightly different appro
|
||||
|
||||
Create phone-home.yaml as follows:
|
||||
|
||||
```
|
||||
```yaml
|
||||
apiVersion: v1
|
||||
kind: Pod
|
||||
metadata:
|
||||
@@ -141,7 +141,7 @@ spec:
|
||||
|
||||
Create your webhook token secret by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
echo -n "imtoosecretformyshorts" > webhook_token.secret
|
||||
kubectl create secret generic traefik-credentials --from-file=webhook_token.secret
|
||||
```
|
||||
@@ -169,20 +169,20 @@ Run ```kubectl create -f phone-home.yaml``` to create the pod.
|
||||
|
||||
Run ```kubectl get pods -o wide``` to confirm that both the phone-home pod and the traefik pod are on the same node:
|
||||
|
||||
```
|
||||
```bash
|
||||
# kubectl get pods -o wide
|
||||
NAME READY STATUS RESTARTS AGE IP NODE
|
||||
phonehome-traefik 1/1 Running 0 20h 10.56.2.55 gke-penguins-are-sexy-8b85ef4d-2c9g
|
||||
traefik-69db67f64c-5666c 1/1 Running 0 10d 10.56.2.30 gkepenguins-are-sexy-8b85ef4d-2c9g
|
||||
```
|
||||
|
||||
Now browse to https://<your load balancer>, and you should get a valid SSL cert, along with a 404 error (_you haven't deployed any other recipes yet_)
|
||||
Now browse to `https://<your load balancer`, and you should get a valid SSL cert, along with a 404 error (_you haven't deployed any other recipes yet_)
|
||||
|
||||
### Making changes
|
||||
|
||||
If you change a value in values.yaml, and want to update the traefik pod, run:
|
||||
|
||||
```
|
||||
```bash
|
||||
helm upgrade --values values.yml traefik stable/traefik --recreate-pods
|
||||
```
|
||||
|
||||
@@ -210,4 +210,4 @@ I'll be adding more Kubernetes versions of existing recipes soon. Check out the
|
||||
|
||||
[^1]: It's kinda lame to be able to bring up Traefik but not to use it. I'll be adding the oauth_proxy element shortly, which will make this last step a little more conclusive and exciting!
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,7 +1,7 @@
|
||||
# Premix Repository
|
||||
|
||||
"Premix" is a private git repository available to [GitHub sponsors](https://github.com/sponsors/funkypenguin), which includes:
|
||||
|
||||
|
||||
1. Necessary docker-compose and env files for all published recipes
|
||||
2. Ansible playbook for deploying the cookbook stack, as well as individual recipes
|
||||
3. Helm charts for deploying recipes into Kubernetes
|
||||
@@ -15,8 +15,8 @@ Generally, each recipe with necessary files is contained within its own folder.
|
||||
Here's a sample of the directory structure:
|
||||
|
||||
??? "What will I find in the pre-mix?"
|
||||
```
|
||||
.
|
||||
```bash
|
||||
.
|
||||
├── README.md
|
||||
├── ansible
|
||||
│ ├── README.md
|
||||
@@ -154,7 +154,7 @@ Here's a sample of the directory structure:
|
||||
│ │ │ └── funkycore-1.0.0.tgz
|
||||
│ │ ├── templates
|
||||
│ │ │ ├── NOTES.txt
|
||||
│ │ │ ├── _helpers.tpl
|
||||
│ │ │ ├──_helpers.tpl
|
||||
│ │ │ ├── apps
|
||||
│ │ │ │ ├── bazarr
|
||||
│ │ │ │ │ ├── config-pvc.yaml
|
||||
@@ -228,7 +228,7 @@ Here's a sample of the directory structure:
|
||||
│ │ │ └── postgresql-8.3.0.tgz
|
||||
│ │ ├── myvalues.yaml
|
||||
│ │ ├── templates
|
||||
│ │ │ ├── _helpers.tpl
|
||||
│ │ │ ├──_helpers.tpl
|
||||
│ │ │ ├── deployment.yaml
|
||||
│ │ │ ├── ingress
|
||||
│ │ │ │ ├── kube.yaml
|
||||
@@ -496,7 +496,7 @@ Here's a sample of the directory structure:
|
||||
│ │ ├── Chart.yaml
|
||||
│ │ ├── templates
|
||||
│ │ │ ├── NOTES.TXT
|
||||
│ │ │ ├── _helpers.tpl
|
||||
│ │ │ ├──_helpers.tpl
|
||||
│ │ │ ├── deployment.yaml
|
||||
│ │ │ ├── ingress
|
||||
│ │ │ │ ├── kube.yaml
|
||||
|
||||
@@ -16,7 +16,7 @@ The ansible playbooks / roles in premix are intended to automate the deployment
|
||||
|
||||
## Details
|
||||
|
||||
**Duplication should be avoided**
|
||||
### Duplication should be avoided
|
||||
|
||||
This means that ansible will use the same source files which we use to deploy swarm stacks manually (*i.e., /kanboard/*). This has some implications:
|
||||
|
||||
@@ -26,7 +26,7 @@ This means that ansible will use the same source files which we use to deploy sw
|
||||
|
||||
In an ansible-based deployment, we **don't** clone the premix repo to /var/data/config. Instead, we clone it somewhere local, and then use the playbook to launch the stack, including the creation of ceph shared storage at /var/data/config. The necessary files are then **copied** from the cloned repo into `/var/data/config`, so that they can be altered by the user, backed up, etc. This separation of code from config makes it easier for users to pull down updates to the premix repo, without having to worry about merge conflicts etc for the files they've manually changed during deployment.
|
||||
|
||||
**Configuration should be centralized**
|
||||
### Configuration should be centralized
|
||||
|
||||
What we _don't_ want, is to manually be editing `<recipe>/<recipe>.env` files all over, and tracking changes to all of these. To this end, there's a `config` dictionary defined, which includes a subsection for each recipe. Here's an example:
|
||||
|
||||
@@ -43,4 +43,4 @@ config:
|
||||
AWS_ACCESS_KEY_ID: {{ "{{ vault_config.traefik.aws_access_key_id }}" }}
|
||||
AWS_SECRET_ACCESS_KEY: {{ "{{ vault_config.traefik.aws_secret_access_key }}" }}
|
||||
AWS_REGION: ""
|
||||
```
|
||||
```
|
||||
|
||||
@@ -16,7 +16,7 @@ Now we'll be creating 3 files..
|
||||
|
||||
Create a new file at `ansible/hosts.your-username` containing a variation on this:
|
||||
|
||||
```
|
||||
```bash
|
||||
[your-username:children]
|
||||
proxmox_servers
|
||||
proxmox_vms
|
||||
@@ -62,11 +62,11 @@ bebop ansible_host=192.168.38.203
|
||||
|
||||
The variables used in the playbook are defined in the `ansible/group_vars/all/main.yml`. **Your** variables are going to be defined in a group_vars file based on your username, so that they're [treated with a higher preference](https://docs.ansible.com/ansible/latest/user_guide/playbooks_variables.html#variable-precedence-where-should-i-put-a-variable) than the default values.
|
||||
|
||||
Create a folder under `ansible/group_vars/<your-username>` to match the group name you inserted in line \#1 of your hosts file, and copy `ansible/group_vars/all/main.yml` into this folder. Any variables found in this file will override any variables specified in `ansible/group_vars/all/main.yml`, but any variables _not_ found in your file will be inherited from `ansible/group_vars/all/main.yml`.
|
||||
Create a folder under `ansible/group_vars/<your-username>` to match the group name you inserted in line \#1 of your hosts file, and copy `ansible/group_vars/all/main.yml` into this folder. Any variables found in this file will override any variables specified in `ansible/group_vars/all/main.yml`, but any variables _not_ found in your file will be inherited from `ansible/group_vars/all/main.yml`.
|
||||
|
||||
To further streamline config, a "empty" dictionary variable named `recipe_config` is configured in `ansible/group_vars/all/main.yml`. In your own vars file (`ansible/group_vars/<your-username>/main.yml`), populate this variable with your own preferred values, copied from `recipe_default_config`. When the playbook runs, your values will be combined with the default values.
|
||||
|
||||
!!! tip "Commit `ansible/group_vars/<your-username>/` to your own repo"
|
||||
!!! tip "Commit `ansible/group_vars/<your-username>/` to your own repo"
|
||||
For extra geek-fu, you could commit the contents of ``ansible/group_vars/<your-username>/` to your own repo, so that you can version/track your own config!
|
||||
|
||||
### Secrets
|
||||
@@ -79,19 +79,19 @@ Enter [Ansible Vault](https://docs.ansible.com/ansible/latest/user_guide/vault.h
|
||||
|
||||
Create a password file, containing a vault password (*just generate one yourself*), and store it _outside_ of the repo:
|
||||
|
||||
```
|
||||
```bash
|
||||
echo mysecretpassword > ~/.ansible/vault-password-geek-cookbook-premix
|
||||
```
|
||||
|
||||
Create an ansible-vault encrypted file in the `group_vars/<your-username>/vault.yml` using this password file:
|
||||
|
||||
```
|
||||
```bash
|
||||
ansible-vault create --vault-id geek-cookbook-premix vars/vault.yml
|
||||
```
|
||||
|
||||
Insert your secret values into this file (*refer to `group_vars/all/01_fake_vault.yml` for placeholders*), using a prefix of `vault_`, like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
vault_proxmox_host_password: mysekritpassword
|
||||
```
|
||||
|
||||
@@ -100,7 +100,7 @@ vault_proxmox_host_password: mysekritpassword
|
||||
The vault file is encrypted using a secret you store outside the repo, and now you can safely check in and version `group_vars/<your-username>/vault.yml` without worrying about exposing secrets in cleartext!
|
||||
|
||||
!!! tip "Editing ansible-vault files with VSCode"
|
||||
If you prefer to edit your vault file using VSCode (*with all its YAML syntax checking*) to nasty-ol' CLI editors, you can set your EDITOR ENV variable by running ` export EDITOR="code --wait"`.
|
||||
If you prefer to edit your vault file using VSCode (*with all its YAML syntax checking*) to nasty-ol' CLI editors, you can set your EDITOR ENV variable by running `export EDITOR="code --wait"`.
|
||||
|
||||
## Serving
|
||||
|
||||
@@ -114,13 +114,13 @@ To run the playbook selectively (i.e., maybe just deploy traefik), add the name
|
||||
|
||||
I.e., to deploy only ceph:
|
||||
|
||||
```
|
||||
```bash
|
||||
ansible-playbook -i hosts.your-username deploy.yml -t ceph
|
||||
```
|
||||
|
||||
To deploy traefik (overlay), traefikv1, and traefik-forward-auth:
|
||||
|
||||
```
|
||||
```bash
|
||||
ansible-playbook -i hosts.your-username deploy.yml -t traefik,traefikv1,traefik-forward-auth
|
||||
```
|
||||
|
||||
@@ -130,7 +130,7 @@ Deploying on full autopilot above installs _a lot_ of stuff (and more is being a
|
||||
|
||||
To deploy the base infrastructure:
|
||||
|
||||
```
|
||||
```bash
|
||||
ansible-playbook -i hosts.your-username deploy.yml -t infrastructure
|
||||
```
|
||||
|
||||
@@ -139,6 +139,3 @@ This will run the playbook up through the `traefik-forward-auth` role and leave
|
||||
### Deploy (with debugging)
|
||||
|
||||
If something went wrong, append `-vv` to your deploy command, for extra-verbose output :thumbsup:
|
||||
|
||||
|
||||
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
# Warning
|
||||
|
||||
!!! warning "This section is under construction :hammer:"
|
||||
This section is a serious work-in-progress, and reflects the current development on the [sponsors](https://github.com/sponsors/funkypenguin)'s "premix" repository
|
||||
So... There may be errors and inaccuracies. Jump into [Discord](http://chat.funkypenguin.co.nz) in the #dev channel if you're encountering issues 😁
|
||||
|
||||
@@ -1,3 +1,5 @@
|
||||
# Warning
|
||||
|
||||
!!! warning "This section is under construction :hammer:"
|
||||
This section is a serious work-in-progress, and reflects the current development on the [sponsors](https://github.com/sponsors/funkypenguin)'s "premix" repository
|
||||
So... There may be errors and inaccuracies. Jump into [Discord](http://chat.funkypenguin.co.nz) in the #dev channel if you're encountering issues 😁
|
||||
|
||||
@@ -1,18 +1,18 @@
|
||||
---
|
||||
description: A self-hosted internet archiving solution
|
||||
---
|
||||
# Archivebox
|
||||
|
||||
|
||||
[ArchiveBox](https://github.com/ArchiveBox/ArchiveBox) is a self-hosted internet archiving solution to collect and save sites you wish to view offline.
|
||||
|
||||

|
||||
|
||||
Features include:
|
||||
|
||||
Features include
|
||||
|
||||
* Uses standard formats such as HTML, JSON, PDF, PNG
|
||||
* Ability to autosave to [archive.org](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#submit_archive_dot_org)
|
||||
* Supports Scheduled importing
|
||||
* Supports Realtime importing
|
||||
|
||||
- Uses standard formats such as HTML, JSON, PDF, PNG
|
||||
- Ability to autosave to [archive.org](https://github.com/ArchiveBox/ArchiveBox/wiki/Configuration#submit_archive_dot_org)
|
||||
- Supports Scheduled importing
|
||||
- Supports Realtime importing
|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
|
||||
@@ -22,7 +22,7 @@ Features include
|
||||
|
||||
First, we create a directory to hold the data which archivebox will store:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/archivebox
|
||||
mkdir /var/data/config/archivebox
|
||||
cd /var/data/config/archivebox
|
||||
@@ -72,22 +72,17 @@ networks:
|
||||
external: true
|
||||
```
|
||||
|
||||
|
||||
### Initalizing Archivebox
|
||||
|
||||
Once you have created the docker file you will need to run the following command to configure archivebox and create an account.
|
||||
`docker run -v /var/data/archivebox:/data -it archivebox/archivebox init --setup`
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Launch Archivebox!
|
||||
|
||||
Launch the Archivebox stack by running ```docker stack deploy archivebox -c <path -to-docker-compose.yml>```
|
||||
|
||||
|
||||
|
||||
[^1]: The inclusion of Archivebox was due to the efforts of @bencey in Discord (Thanks Ben!)
|
||||
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,8 +1,8 @@
|
||||
# Launch Autopirate stack
|
||||
|
||||
!!! warning
|
||||
This is not a complete recipe - it's the conclusion to the [AutoPirate](/recipes/autopirate/) "_uber-recipe_", but has been split into its own page to reduce complexity.
|
||||
|
||||
### Launch Autopirate stack
|
||||
|
||||
Launch the AutoPirate stack by running ```docker stack deploy autopirate -c <path -to-docker-compose.yml>```
|
||||
|
||||
Confirm the container status by running "docker stack ps autopirate", and wait for all containers to enter the "Running" state.
|
||||
@@ -11,4 +11,4 @@ Log into each of your new tools at its respective HTTPS URL. You'll be prompted
|
||||
|
||||
[^1]: This is a complex stack. Sing out in the comments if you found a flaw or need a hand :)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
description: Headphones is an automated music downloader for NZB and BitTorrent
|
||||
---
|
||||
# Headphones
|
||||
|
||||
!!! warning
|
||||
This is not a complete recipe - it's a component of the [autopirate](/recipes/autopirate/) "_uber-recipe_", but has been split into its own page to reduce complexity.
|
||||
|
||||
@@ -51,4 +52,4 @@ headphones_proxy:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
description: Heimdall is a beautiful dashboard for all your web applications
|
||||
---
|
||||
# Heimdall
|
||||
|
||||
!!! warning
|
||||
This is not a complete recipe - it's a component of the [autopirate](/recipes/autopirate/) "_uber-recipe_", but has been split into its own page to reduce complexity.
|
||||
|
||||
|
||||
@@ -6,7 +6,7 @@ description: A fully-featured recipe to automate finding, downloading, and organ
|
||||
|
||||
Once the cutting edge of the "internet" (_pre-world-wide-web and mosiac days_), Usenet is now a murky, geeky alternative to torrents for file-sharing. However, it's **cool** geeky, especially if you're into having a fully automated media platform.
|
||||
|
||||
A good starter for the usenet scene is https://www.reddit.com/r/usenet/. Because it's so damn complicated, a host of automated tools exist to automate the process of finding, downloading, and managing content. The tools included in this recipe are as follows:
|
||||
A good starter for the usenet scene is <https://www.reddit.com/r/usenet/>. Because it's so damn complicated, a host of automated tools exist to automate the process of finding, downloading, and managing content. The tools included in this recipe are as follows:
|
||||
|
||||

|
||||
|
||||
@@ -25,7 +25,7 @@ Tools included in the AutoPirate stack are:
|
||||
* [NZBHydra][nzbhydra] is a meta search for NZB indexers. It provides easy access to a number of raw and newznab based indexers. You can search all your indexers from one place and use it as indexer source for tools like [Sonarr][sonarr] or [Radarr][radarr].
|
||||
|
||||
* [Sonarr][sonarr] finds, downloads and manages TV shows
|
||||
|
||||
|
||||
* [Radarr][radarr] finds, downloads and manages movies
|
||||
|
||||
* [Readarr][readarr] finds, downloads, and manages eBooks
|
||||
@@ -44,7 +44,6 @@ Tools included in the AutoPirate stack are:
|
||||
|
||||
Since this recipe is so long, and so many of the tools are optional to the final result (_i.e., if you're not interested in comics, you won't want Mylar_), I've described each individual tool on its own sub-recipe page (_below_), even though most of them are deployed very similarly.
|
||||
|
||||
|
||||
## Ingredients
|
||||
|
||||
!!! summary "Ingredients"
|
||||
@@ -88,9 +87,9 @@ To mitigate the risk associated with public exposure of these tools (_you're on
|
||||
|
||||
This is tedious, but you only have to do it once. Each tool (Sonarr, Radarr, etc) to be protected by an OAuth proxy, requires unique configuration. I use github to provide my oauth, giving each tool a unique logo while I'm at it (make up your own random string for OAUTH2PROXYCOOKIE_SECRET)
|
||||
|
||||
For each tool, create /var/data/autopirate/<tool>.env, and set the following:
|
||||
For each tool, create `/var/data/autopirate/<tool>.env`, and set the following:
|
||||
|
||||
```
|
||||
```bash
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
OAUTH2_PROXY_COOKIE_SECRET=
|
||||
@@ -98,7 +97,7 @@ PUID=4242
|
||||
PGID=4242
|
||||
```
|
||||
|
||||
Create at least /var/data/autopirate/authenticated-emails.txt, containing at least your own email address with your OAuth provider. If you wanted to grant access to a specific tool to other users, you'd need a unique authenticated-emails-<tool>.txt which included both normal email address as well as any addresses to be granted tool-specific access.
|
||||
Create at least /var/data/autopirate/authenticated-emails.txt, containing at least your own email address with your OAuth provider. If you wanted to grant access to a specific tool to other users, you'd need a unique `authenticated-emails-<tool>.txt` which included both normal email address as well as any addresses to be granted tool-specific access.
|
||||
|
||||
### Setup components
|
||||
|
||||
@@ -106,7 +105,7 @@ Create at least /var/data/autopirate/authenticated-emails.txt, containing at lea
|
||||
|
||||
**Start** with a swarm config file in docker-compose syntax, like this:
|
||||
|
||||
````
|
||||
````yaml
|
||||
version: '3'
|
||||
|
||||
services:
|
||||
@@ -114,7 +113,7 @@ services:
|
||||
|
||||
And **end** with a stanza like this:
|
||||
|
||||
````
|
||||
````yaml
|
||||
networks:
|
||||
traefik_public:
|
||||
external: true
|
||||
@@ -127,4 +126,4 @@ networks:
|
||||
|
||||
--8<-- "reference-networks.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -47,4 +47,4 @@ jackett:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -3,6 +3,7 @@ description: LazyLibrarian is a tool to follow authors and grab metadata for all
|
||||
---
|
||||
|
||||
# LazyLibrarian
|
||||
|
||||
!!! warning
|
||||
This is not a complete recipe - it's a component of the [autopirate](/recipes/autopirate/) "_uber-recipe_", but has been split into its own page to reduce complexity.
|
||||
|
||||
@@ -61,4 +62,4 @@ calibre-server:
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
[^2]: The calibre-server container co-exists within the Lazy Librarian (LL) containers so that LL can automatically add a book to Calibre using the calibre-server interface. The calibre library can then be properly viewed using the [calibre-web](/recipes/calibre-web) recipe.
|
||||
[^2]: The calibre-server container co-exists within the Lazy Librarian (LL) containers so that LL can automatically add a book to Calibre using the calibre-server interface. The calibre library can then be properly viewed using the [calibre-web](/recipes/calibre-web) recipe.
|
||||
|
||||
@@ -2,6 +2,7 @@
|
||||
description: Lidarr is an automated music downloader for NZB and Torrent
|
||||
---
|
||||
# Lidarr
|
||||
|
||||
!!! warning
|
||||
This is not a complete recipe - it's a component of the [autopirate](/recipes/autopirate/) "_uber-recipe_", but has been split into its own page to reduce complexity.
|
||||
|
||||
|
||||
@@ -49,7 +49,6 @@ nzbget:
|
||||
|
||||
[^tfa]: Since we're relying on [Traefik Forward Auth][tfa] to protect us, we can just disable NZGet's own authentication, by changing ControlPassword to null in nzbget.conf (i.e. ```ControlPassword=```)
|
||||
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -62,4 +62,4 @@ nzbhydra2:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -60,4 +60,4 @@ radarr:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -4,6 +4,7 @@ description: Readarr is "Sonarr/Radarr for eBooks"
|
||||
|
||||
|
||||
# Readarr
|
||||
|
||||
!!! warning
|
||||
This is not a complete recipe - it's a component of the [AutoPirate](/recipes/autopirate/) "_uber-recipe_", but has been split into its own page to reduce complexity.
|
||||
|
||||
@@ -23,7 +24,6 @@ Features include:
|
||||
* Full integration with [Calibre][calibre-web] (add to library, conversion)
|
||||
* And a beautiful UI!
|
||||
|
||||
|
||||
## Inclusion into AutoPirate
|
||||
|
||||
To include Readarr in your [AutoPirate][autopirate] stack, include something like the following in your autopirate.yml stack definition file:
|
||||
@@ -59,4 +59,4 @@ radarr:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -52,4 +52,4 @@ rtorrent:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -58,4 +58,4 @@ sabnzbd:
|
||||
For example, mine simply reads ```host_whitelist = sabnzbd.funkypenguin.co.nz, sabnzbd```
|
||||
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -46,4 +46,4 @@ sonarr:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
--8<-- "recipe-autopirate-toc.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -32,9 +32,10 @@ Bitwarden is a free and open source password management solution for individuals
|
||||
|
||||
We'll need to create a directory to bind-mount into our container, so create `/var/data/bitwarden`:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/bitwarden
|
||||
```
|
||||
|
||||
### Setup environment
|
||||
|
||||
Create `/var/data/config/bitwarden/bitwarden.env`, and **leave it empty for now**.
|
||||
@@ -86,7 +87,6 @@ networks:
|
||||
!!! note
|
||||
Note the clever use of two Traefik frontends to expose the notifications hub on port 3012. Thanks @gkoerk!
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Launch Bitwarden stack
|
||||
@@ -97,7 +97,7 @@ Browse to your new instance at https://**YOUR-FQDN**, and create a new user acco
|
||||
|
||||
### Get the apps / extensions
|
||||
|
||||
Once you've created your account, jump over to https://bitwarden.com/#download and download the apps for your mobile and browser, and start adding your logins!
|
||||
Once you've created your account, jump over to <https://bitwarden.com/#download> and download the apps for your mobile and browser, and start adding your logins!
|
||||
|
||||
[^1]: You'll notice we're not using the *official* container images (*[all 6 of them required](https://help.bitwarden.com/article/install-on-premise/#install-bitwarden)!)*, but rather a [more lightweight version ideal for self-hosting](https://hub.docker.com/r/vaultwarden/server). All of the elements are contained within a single container, and SQLite is used for the database backend.
|
||||
[^2]: As mentioned above, readers should refer to the [dani-garcia/vaultwarden wiki](https://github.com/dani-garcia/vaultwarden) for details on customizing the behaviour of Bitwarden.
|
||||
|
||||
@@ -20,7 +20,7 @@ I like to protect my public-facing web UIs with an [oauth_proxy](/reference/oaut
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/bookstack:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/bookstack/database-dump
|
||||
mkdir -p /var/data/runtime/bookstack/db
|
||||
```
|
||||
@@ -29,7 +29,7 @@ mkdir -p /var/data/runtime/bookstack/db
|
||||
|
||||
Create bookstack.env, and populate with the following variables. Set the [oauth_proxy](/reference/oauth_proxy) variables provided by your OAuth provider (if applicable.)
|
||||
|
||||
```
|
||||
```bash
|
||||
# For oauth-proxy (optional)
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
@@ -136,4 +136,4 @@ Log into your new instance at https://**YOUR-FQDN**, authenticate with oauth_pro
|
||||
|
||||
[^1]: If you wanted to expose the BookStack UI directly, you could remove the oauth2_proxy from the design, and move the traefik_public-related labels directly to the bookstack container. You'd also need to add the traefik_public network to the bookstack container.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -22,7 +22,6 @@ Support for editing eBook metadata and deleting eBooks from Calibre library
|
||||
* Support for reading eBooks directly in the browser (.txt, .epub, .pdf, .cbr, .cbt, .cbz)
|
||||
* Upload new books in PDF, epub, fb2 format
|
||||
|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
|
||||
## Preparation
|
||||
@@ -31,7 +30,7 @@ Support for editing eBook metadata and deleting eBooks from Calibre library
|
||||
|
||||
We'll need a directory to store some config data for Calibre-Web, container, so create /var/data/calibre-web, and ensure the directory is owned by the same use which owns your Calibre data (below)
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/calibre-web
|
||||
chown calibre:calibre /var/data/calibre-web # for example
|
||||
```
|
||||
@@ -42,7 +41,7 @@ Ensure that your Calibre library is accessible to the swarm (_i.e., exists on sh
|
||||
|
||||
We'll use an [oauth-proxy](/reference/oauth_proxy/) to protect the UI from public access, so create calibre-web.env, and populate with the following variables:
|
||||
|
||||
```
|
||||
```bash
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
OAUTH2_PROXY_COOKIE_SECRET=<make this a random string>
|
||||
@@ -52,7 +51,6 @@ PGID=
|
||||
|
||||
Follow the [instructions](https://github.com/bitly/oauth2_proxy) to setup your oauth provider. You need to setup a unique key/secret for each instance of the proxy you want to run, since in each case the callback URL will differ.
|
||||
|
||||
|
||||
### Setup Docker Swarm
|
||||
|
||||
Create a docker swarm config file in docker-compose syntax (v3), something like this:
|
||||
@@ -118,4 +116,4 @@ Log into your new instance at https://**YOUR-FQDN**. You'll be directed to the i
|
||||
[^1]: Yes, Calibre does provide a server component. But it's not as fully-featured as Calibre-Web (_i.e., you can't use it to send ebooks directly to your Kindle_)
|
||||
[^2]: A future enhancement might be integrating this recipe with the filestore for [NextCloud](/recipes/nextcloud/), so that the desktop database (Calibre) can be kept synced with Calibre-Web.
|
||||
[^3]: If you plan to use calibre-web to send `.mobi` files to your Kindle via `@kindle.com` email addresses, be sure to add the sending address to the "[Approved Personal Documents Email List](https://www.amazon.com/hz/mycd/myx#/home/settings/payment)"
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -30,7 +30,7 @@ This presents another problem though - Docker Swarm with Traefik is superb at ma
|
||||
|
||||
We run a single swarmed Nginx instance, which forwards all requests to an upstream, with the target IP of the docker0 interface, on port 9980 (_the port exposed by the CODE container_)
|
||||
|
||||
We attach the necessary labels to the Nginx container to instruct Trafeik to setup a front/backend for collabora.<ourdomain\>. Now incoming requests to **https://collabora.<ourdomain\>** will hit Traefik, be forwarded to nginx (_wherever in the swarm it's running_), and then to port 9980 on the same node that nginx is running on.
|
||||
We attach the necessary labels to the Nginx container to instruct Trafeik to setup a front/backend for collabora.<ourdomain\>. Now incoming requests to `https://collabora.<ourdomain\>` will hit Traefik, be forwarded to nginx (_wherever in the swarm it's running_), and then to port 9980 on the same node that nginx is running on.
|
||||
|
||||
What if we're running multiple nodes in our swarm, and nginx ends up on a different node to the one running Collabora via docker-compose? Well, either constrain nginx to the same node as Collabora (_example below_), or just launch an instance of Collabora on _every_ node then. It's just a rendering / GUI engine after all, it doesn't hold any persistent data.
|
||||
|
||||
@@ -42,7 +42,7 @@ Here's a (_highly technical_) diagram to illustrate:
|
||||
|
||||
We'll need a directory for holding config to bind-mount into our containers, so create ```/var/data/collabora```, and ```/var/data/config/collabora``` for holding the docker/swarm config
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/collabora/
|
||||
mkdir /var/data/config/collabora/
|
||||
```
|
||||
@@ -59,7 +59,7 @@ Create /var/data/config/collabora/collabora.env, and populate with the following
|
||||
3. Set your server_name to collabora.<yourdomain\>. Escaping periods is unnecessary
|
||||
4. Your password cannot include triangular brackets - the entrypoint script will insert this password into an XML document, and triangular brackets will make bad(tm) things happen 🔥
|
||||
|
||||
```
|
||||
```bash
|
||||
username=admin
|
||||
password=ilovemypassword
|
||||
domain=nextcloud\.batcave\.com
|
||||
@@ -93,8 +93,7 @@ services:
|
||||
|
||||
Create ```/var/data/config/collabora/nginx.conf``` as follows, changing the ```server_name``` value to match the environment variable you established above:
|
||||
|
||||
|
||||
```
|
||||
```ini
|
||||
upstream collabora-upstream {
|
||||
# Run collabora under docker-compose, since it needs MKNOD cap, which can't be provided by Docker Swarm.
|
||||
# The IP here is the typical IP of docker0 - change if yours is different.
|
||||
@@ -128,7 +127,7 @@ server {
|
||||
|
||||
# Admin Console websocket
|
||||
location ^~ /lool/adminws {
|
||||
proxy_buffering off;
|
||||
proxy_buffering off;
|
||||
proxy_pass http://collabora-upstream;
|
||||
proxy_set_header Upgrade $http_upgrade;
|
||||
proxy_set_header Connection "Upgrade";
|
||||
@@ -160,7 +159,7 @@ Create `/var/data/config/collabora/collabora.yml` as follows, changing the traef
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: "3.0"
|
||||
|
||||
services:
|
||||
@@ -195,14 +194,14 @@ Well. This is awkward. There's no documented way to make Collabora work with Doc
|
||||
|
||||
Launching Collabora is (_for now_) a 2-step process. First.. we launch collabora itself, by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
cd /var/data/config/collabora/
|
||||
docker-compose -d up
|
||||
```
|
||||
|
||||
Output looks something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
root@ds1:/var/data/config/collabora# docker-compose up -d
|
||||
WARNING: The Docker Engine you're using is running in swarm mode.
|
||||
|
||||
@@ -230,19 +229,19 @@ Now exec into the container (_from another shell session_), by running ```exec <
|
||||
|
||||
Delete the collabora container by hitting CTRL-C in the docker-compose shell, running ```docker-compose rm```, and then altering this line in docker-compose.yml:
|
||||
|
||||
```
|
||||
- /var/data/collabora/loolwsd.xml:/etc/loolwsd/loolwsd.xml-new
|
||||
```bash
|
||||
- /var/data/collabora/loolwsd.xml:/etc/loolwsd/loolwsd.xml-new
|
||||
```
|
||||
|
||||
To this:
|
||||
|
||||
```
|
||||
- /var/data/collabora/loolwsd.xml:/etc/loolwsd/loolwsd.xml
|
||||
```bash
|
||||
- /var/data/collabora/loolwsd.xml:/etc/loolwsd/loolwsd.xml
|
||||
```
|
||||
|
||||
Edit /var/data/collabora/loolwsd.xml, find the **storage.filesystem.wopi** section, and add lines like this to the existing allow rules (_to allow IPv6-enabled hosts to still connect with their IPv4 addreses_):
|
||||
|
||||
```
|
||||
```xml
|
||||
<host desc="Regex pattern of hostname to allow or deny." allow="true">::ffff:10\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}</host>
|
||||
<host desc="Regex pattern of hostname to allow or deny." allow="true">::ffff:172\.1[6789]\.[0-9]{1,3}\.[0-9]{1,3}</host>
|
||||
<host desc="Regex pattern of hostname to allow or deny." allow="true">::ffff:172\.2[0-9]\.[0-9]{1,3}\.[0-9]{1,3}</host>
|
||||
@@ -252,7 +251,7 @@ Edit /var/data/collabora/loolwsd.xml, find the **storage.filesystem.wopi** secti
|
||||
|
||||
Find the **net.post_allow** section, and add a line like this:
|
||||
|
||||
```
|
||||
```xml
|
||||
<host desc="RFC1918 private addressing in inet6 format">::ffff:10\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}</host>
|
||||
<host desc="RFC1918 private addressing in inet6 format">::ffff:172\.1[6789]\.[0-9]{1,3}\.[0-9]{1,3}</host>
|
||||
<host desc="RFC1918 private addressing in inet6 format">::ffff:172\.2[0-9]\.[0-9]{1,3}\.[0-9]{1,3}</host>
|
||||
@@ -262,35 +261,35 @@ Find the **net.post_allow** section, and add a line like this:
|
||||
|
||||
Find these 2 lines:
|
||||
|
||||
```
|
||||
```xml
|
||||
<ssl desc="SSL settings">
|
||||
<enable type="bool" default="true">true</enable>
|
||||
```
|
||||
|
||||
And change to:
|
||||
|
||||
```
|
||||
```xml
|
||||
<ssl desc="SSL settings">
|
||||
<enable type="bool" default="true">false</enable>
|
||||
```
|
||||
|
||||
Now re-launch collabora (_with the correct with loolwsd.xml_) under docker-compose, by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
docker-compose -d up
|
||||
```
|
||||
|
||||
Once collabora is up, we launch the swarm stack, by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
docker stack deploy collabora -c /var/data/config/collabora/collabora.yml
|
||||
```
|
||||
|
||||
Visit **https://collabora.<yourdomain\>/l/loleaflet/dist/admin/admin.html** and confirm you can login with the user/password you specified in collabora.env
|
||||
Visit `https://collabora.<yourdomain\>/l/loleaflet/dist/admin/admin.html` and confirm you can login with the user/password you specified in collabora.env
|
||||
|
||||
### Integrate into NextCloud
|
||||
|
||||
In NextCloud, Install the **Collabora Online** app (https://apps.nextcloud.com/apps/richdocuments), and then under **Settings -> Collabora Online**, set your Collabora Online Server to ```https://collabora.<your domain>```
|
||||
In NextCloud, Install the **Collabora Online** app (<https://apps.nextcloud.com/apps/richdocuments>), and then under **Settings -> Collabora Online**, set your Collabora Online Server to ```https://collabora.<your domain>```
|
||||
|
||||

|
||||
|
||||
@@ -298,4 +297,4 @@ Now browse your NextCloud files. Click the plus (+) sign to create a new documen
|
||||
|
||||
[^1]: Yes, this recipe is complicated. And you probably only care if you feel strongly about using Open Source rich document editing in the browser, vs using something like Google Docs. It works impressively well however, once it works. I hope to make this recipe simpler once the CODE developers have documented how to pass optional parameters as environment variables.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -14,10 +14,10 @@ Are you a [l33t h@x0r](https://en.wikipedia.org/wiki/Hackers_(film))? Do you nee
|
||||
|
||||
Here are some examples of fancy hax0r tricks you can do with CyberChef:
|
||||
|
||||
- [Decode a Base64-encoded string][2]
|
||||
- [Decrypt and disassemble shellcode][6]
|
||||
- [Perform AES decryption, extracting the IV from the beginning of the cipher stream][10]
|
||||
- [Automagically detect several layers of nested encoding][12]
|
||||
- [Decode a Base64-encoded string][2]
|
||||
- [Decrypt and disassemble shellcode][6]
|
||||
- [Perform AES decryption, extracting the IV from the beginning of the cipher stream][10]
|
||||
- [Automagically detect several layers of nested encoding][12]
|
||||
|
||||
Here's a [live demo](https://gchq.github.io/CyberChef)!
|
||||
|
||||
@@ -70,4 +70,4 @@ Launch your CyberChef stack by running ```docker stack deploy cyberchef -c <path
|
||||
[2]: https://gchq.github.io/CyberChef/#recipe=From_Base64('A-Za-z0-9%2B/%3D',true)&input=VTI4Z2JHOXVaeUJoYm1RZ2RHaGhibXR6SUdadmNpQmhiR3dnZEdobElHWnBjMmd1
|
||||
[6]: https://gchq.github.io/CyberChef/#recipe=RC4(%7B'option':'UTF8','string':'secret'%7D,'Hex','Hex')Disassemble_x86('64','Full%20x86%20architecture',16,0,true,true)&input=MjFkZGQyNTQwMTYwZWU2NWZlMDc3NzEwM2YyYTM5ZmJlNWJjYjZhYTBhYWJkNDE0ZjkwYzZjYWY1MzEyNzU0YWY3NzRiNzZiM2JiY2QxOTNjYjNkZGZkYmM1YTI2NTMzYTY4NmI1OWI4ZmVkNGQzODBkNDc0NDIwMWFlYzIwNDA1MDcxMzhlMmZlMmIzOTUwNDQ2ZGIzMWQyYmM2MjliZTRkM2YyZWIwMDQzYzI5M2Q3YTVkMjk2MmMwMGZlNmRhMzAwNzJkOGM1YTZiNGZlN2Q4NTlhMDQwZWVhZjI5OTczMzYzMDJmNWEwZWMxOQ
|
||||
[10]: https://gchq.github.io/CyberChef/#recipe=Register('(.%7B32%7D)',true,false)Drop_bytes(0,32,false)AES_Decrypt(%7B'option':'Hex','string':'1748e7179bd56570d51fa4ba287cc3e5'%7D,%7B'option':'Hex','string':'$R0'%7D,'CTR','Hex','Raw',%7B'option':'Hex','string':''%7D)&input=NTFlMjAxZDQ2MzY5OGVmNWY3MTdmNzFmNWI0NzEyYWYyMGJlNjc0YjNiZmY1M2QzODU0NjM5NmVlNjFkYWFjNDkwOGUzMTljYTNmY2Y3MDg5YmZiNmIzOGVhOTllNzgxZDI2ZTU3N2JhOWRkNmYzMTFhMzk0MjBiODk3OGU5MzAxNGIwNDJkNDQ3MjZjYWVkZjU0MzZlYWY2NTI0MjljMGRmOTRiNTIxNjc2YzdjMmNlODEyMDk3YzI3NzI3M2M3YzcyY2Q4OWFlYzhkOWZiNGEyNzU4NmNjZjZhYTBhZWUyMjRjMzRiYTNiZmRmN2FlYjFkZGQ0Nzc2MjJiOTFlNzJjOWU3MDlhYjYwZjhkYWY3MzFlYzBjYzg1Y2UwZjc0NmZmMTU1NGE1YTNlYzI5MWNhNDBmOWU2MjlhODcyNTkyZDk4OGZkZDgzNDUzNGFiYTc5YzFhZDE2NzY3NjlhN2MwMTBiZjA0NzM5ZWNkYjY1ZDk1MzAyMzcxZDYyOWQ5ZTM3ZTdiNGEzNjFkYTQ2OGYxZWQ1MzU4OTIyZDJlYTc1MmRkMTFjMzY2ZjMwMTdiMTRhYTAxMWQyYWYwM2M0NGY5NTU3OTA5OGExNWUzY2Y5YjQ0ODZmOGZmZTljMjM5ZjM0ZGU3MTUxZjZjYTY1MDBmZTRiODUwYzNmMWMwMmU4MDFjYWYzYTI0NDY0NjE0ZTQyODAxNjE1YjhmZmFhMDdhYzgyNTE0OTNmZmRhN2RlNWRkZjMzNjg4ODBjMmI5NWIwMzBmNDFmOGYxNTA2NmFkZDA3MWE2NmNmNjBlNWY0NmYzYTIzMGQzOTdiNjUyOTYzYTIxYTUzZg
|
||||
[12]: https://gchq.github.io/CyberChef/#recipe=Magic(3,false,false)&input=V1VhZ3dzaWFlNm1QOGdOdENDTFVGcENwQ0IyNlJtQkRvREQ4UGFjZEFtekF6QlZqa0syUXN0RlhhS2hwQzZpVVM3UkhxWHJKdEZpc29SU2dvSjR3aGptMWFybTg2NHFhTnE0UmNmVW1MSHJjc0FhWmM1VFhDWWlmTmRnUzgzZ0RlZWpHWDQ2Z2FpTXl1QlY2RXNrSHQxc2NnSjg4eDJ0TlNvdFFEd2JHWTFtbUNvYjJBUkdGdkNLWU5xaU45aXBNcTFaVTFtZ2tkYk51R2NiNzZhUnRZV2hDR1VjOGc5M1VKdWRoYjhodHNoZVpud1RwZ3FoeDgzU1ZKU1pYTVhVakpUMnptcEM3dVhXdHVtcW9rYmRTaTg4WXRrV0RBYzFUb291aDJvSDRENGRkbU5LSldVRHBNd21uZ1VtSzE0eHdtb21jY1BRRTloTTE3MkFQblNxd3hkS1ExNzJSa2NBc3lzbm1qNWdHdFJtVk5OaDJzMzU5d3I2bVMyUVJQ
|
||||
[12]: https://gchq.github.io/CyberChef/#recipe=Magic(3,false,false)&input=V1VhZ3dzaWFlNm1QOGdOdENDTFVGcENwQ0IyNlJtQkRvREQ4UGFjZEFtekF6QlZqa0syUXN0RlhhS2hwQzZpVVM3UkhxWHJKdEZpc29SU2dvSjR3aGptMWFybTg2NHFhTnE0UmNmVW1MSHJjc0FhWmM1VFhDWWlmTmRnUzgzZ0RlZWpHWDQ2Z2FpTXl1QlY2RXNrSHQxc2NnSjg4eDJ0TlNvdFFEd2JHWTFtbUNvYjJBUkdGdkNLWU5xaU45aXBNcTFaVTFtZ2tkYk51R2NiNzZhUnRZV2hDR1VjOGc5M1VKdWRoYjhodHNoZVpud1RwZ3FoeDgzU1ZKU1pYTVhVakpUMnptcEM3dVhXdHVtcW9rYmRTaTg4WXRrV0RBYzFUb291aDJvSDRENGRkbU5LSldVRHBNd21uZ1VtSzE0eHdtb21jY1BRRTloTTE3MkFQblNxd3hkS1ExNzJSa2NBc3lzbm1qNWdHdFJtVk5OaDJzMzU5d3I2bVMyUVJQ
|
||||
|
||||
@@ -8,7 +8,6 @@ Always have a backup plan[^1]
|
||||
|
||||

|
||||
|
||||
|
||||
[Duplicati](https://www.duplicati.com/) is a free and open-source backup software to store encrypted backups online For Windows, macOS and Linux (our favorite, yay!).
|
||||
|
||||
Similar to the other backup options in the Cookbook, we can use Duplicati to backup all our data-at-rest to a wide variety of locations, including, but not limited to:
|
||||
@@ -23,7 +22,7 @@ Similar to the other backup options in the Cookbook, we can use Duplicati to bac
|
||||
## Ingredients
|
||||
|
||||
!!! summary "Ingredients"
|
||||
* [X] [Docker swarm cluster](/ha-docker-swarm/design/) with [persistent shared storage](/ha-docker-swarm/shared-storage-ceph.md)
|
||||
*[X] [Docker swarm cluster](/ha-docker-swarm/design/) with [persistent shared storage](/ha-docker-swarm/shared-storage-ceph.md)
|
||||
* [X] [Traefik](/ha-docker-swarm/traefik) and [Traefik-Forward-Auth](/ha-docker-swarm/traefik-forward-auth) configured per design
|
||||
* [X] Credentials for one of the Duplicati's supported upload destinations
|
||||
|
||||
@@ -33,7 +32,7 @@ Similar to the other backup options in the Cookbook, we can use Duplicati to bac
|
||||
|
||||
We'll need a folder to store a docker-compose configuration file and an associated environment file. If you're following my filesystem layout, create `/var/data/config/duplicati` (*for the config*), and `/var/data/duplicati` (*for the metadata*) as follows:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/config/duplicati
|
||||
mkdir /var/data/duplicati
|
||||
cd /var/data/config/duplicati
|
||||
@@ -44,7 +43,8 @@ cd /var/data/config/duplicati
|
||||
1. Generate a random passphrase to use to encrypt your data. **Save this somewhere safe**, without it you won't be able to restore!
|
||||
2. Seriously, **save**. **it**. **somewhere**. **safe**.
|
||||
3. Create `duplicati.env`, and populate with the following variables (_replace "Europe/London" with your appropriate time zone from [this list](https://en.wikipedia.org/wiki/List_of_tz_database_time_zones)_)
|
||||
```
|
||||
|
||||
```bash
|
||||
PUID=0
|
||||
PGID=0
|
||||
TZ=Europe/London
|
||||
@@ -54,7 +54,6 @@ CLI_ARGS= #optional
|
||||
!!! question "Excuse me! Why are we running Duplicati as root?"
|
||||
That's a great question! We're running Duplicati as the `root` user of the host system because we need Duplicati to be able to read files of all the other services no matter which user that service is running as. After all, Duplicati can't backup your exciting stuff if it can't read the files.
|
||||
|
||||
|
||||
### Setup Docker Swarm
|
||||
|
||||
Create a docker swarm config file in docker-compose syntax (v3), something like this:
|
||||
@@ -114,7 +113,8 @@ networks:
|
||||
Launch the Duplicati stack by running ```docker stack deploy duplicati -c <path-to-docker-compose.yml>```
|
||||
|
||||
### Create (and verify!) Your First Backup
|
||||
Once we authenticate through the traefik-forward-auth provider, we can start configuring your backup jobs via the Duplicati UI. All backup and restore job configuration is done through the UI. Be sure to read through the documentation on [Creating a new backup job](https://duplicati.readthedocs.io/en/latest/03-using-the-graphical-user-interface/#creating-a-new-backup-job) and [Restoring files from a backup](https://duplicati.readthedocs.io/en/latest/03-using-the-graphical-user-interface/#restoring-files-from-a-backup) for information on how to configure those jobs.
|
||||
|
||||
Once we authenticate through the traefik-forward-auth provider, we can start configuring your backup jobs via the Duplicati UI. All backup and restore job configuration is done through the UI. Be sure to read through the documentation on [Creating a new backup job](https://duplicati.readthedocs.io/en/latest/03-using-the-graphical-user-interface/#creating-a-new-backup-job) and [Restoring files from a backup](https://duplicati.readthedocs.io/en/latest/03-using-the-graphical-user-interface/#restoring-files-from-a-backup) for information on how to configure those jobs.
|
||||
|
||||
!!! warning
|
||||
An untested backup is not really a backup at all. Being ***sure*** you can succesfully restore files from your backup now could save you lots of heartache later after "something bad" happens.
|
||||
|
||||
@@ -1,4 +1,6 @@
|
||||
hero: Duplicity - A boring recipe to backup your exciting stuff. Boring is good.
|
||||
---
|
||||
description: A boring recipe to backup your exciting stuff. Boring is good.
|
||||
---
|
||||
|
||||
# Duplicity
|
||||
|
||||
@@ -54,7 +56,7 @@ I didn't already have an archival/backup provider, so I chose Google Cloud "clou
|
||||
2. Seriously, **save**. **it**. **somewhere**. **safe**.
|
||||
3. Create duplicity.env, and populate with the following variables
|
||||
|
||||
```
|
||||
```bash
|
||||
SRC=/var/data/
|
||||
DST=gs://jack-and-jills-bucket/yes-you-can-have-subdirectories
|
||||
TMPDIR=/tmp
|
||||
@@ -72,7 +74,7 @@ See the [data layout reference](/reference/data_layout/) for an explanation of t
|
||||
|
||||
Before we launch the automated daily backups, let's run a test backup, as follows:
|
||||
|
||||
```
|
||||
```bash
|
||||
docker run --env-file duplicity.env -it --rm -v \
|
||||
/var/data:/var/data:ro -v /var/data/duplicity/tmp:/tmp -v \
|
||||
/var/data/duplicity/archive:/archive tecnativa/duplicity \
|
||||
@@ -101,7 +103,7 @@ duplicity list-current-files \
|
||||
|
||||
Once you've identified a file to test-restore, use a variation of the following to restore it to /tmp (_from the perspective of the container - it's actually /var/data/duplicity/tmp_)
|
||||
|
||||
```
|
||||
```bash
|
||||
docker run --env-file duplicity.env -it --rm \
|
||||
-v /var/data:/var/data:ro \
|
||||
-v /var/data/duplicity/tmp:/tmp \
|
||||
@@ -119,7 +121,7 @@ Now that we have confidence in our backup/restore process, let's automate it by
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: "3"
|
||||
|
||||
services:
|
||||
@@ -156,4 +158,4 @@ Nothing will happen. Very boring. But when the cron script fires (daily), duplic
|
||||
[^1]: Automatic backup can still fail if nobody checks that it's running successfully. I'll be working on an upcoming recipe to monitor the elements of the stack, including the success/failure of duplicity jobs.
|
||||
[^2]: The container provides the facility to specify an SMTP host and port, but not credentials, which makes it close to useless. As a result, I've left SMTP out of this recipe. To enable email notifications (if your SMTP server doesn't require auth), add `SMTP_HOST`, `SMTP_PORT`, `EMAIL_FROM` and `EMAIL_TO` variables to `duplicity.env`.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -6,6 +6,7 @@ description: Real heroes backup their shizz!
|
||||
|
||||
Don't be like [Cameron](http://haltandcatchfire.wikia.com/wiki/Cameron_Howe). Backup your stuff.
|
||||
|
||||
<!-- markdownlint-disable MD033 -->
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/1UtFeMoqVHQ" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
|
||||
|
||||
ElkarBackup is a free open-source backup solution based on RSync/RSnapshot. It's basically a web wrapper around rsync/rsnapshot, which means that your backups are just files on a filesystem, utilising hardlinks for tracking incremental changes. I find this result more reassuring than a blob of compressed, (encrypted?) data that [more sophisticated backup solutions](/recipes/duplicity/) would produce for you.
|
||||
@@ -22,7 +23,7 @@ ElkarBackup is a free open-source backup solution based on RSync/RSnapshot. It's
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/elkarbackup:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/elkarbackup/{backups,uploads,sshkeys,database-dump}
|
||||
mkdir -p /var/data/runtime/elkarbackup/db
|
||||
mkdir -p /var/data/config/elkarbackup
|
||||
@@ -31,7 +32,8 @@ mkdir -p /var/data/config/elkarbackup
|
||||
### Prepare environment
|
||||
|
||||
Create /var/data/config/elkarbackup/elkarbackup.env, and populate with the following variables
|
||||
```
|
||||
|
||||
```bash
|
||||
SYMFONY__DATABASE__PASSWORD=password
|
||||
EB_CRON=enabled
|
||||
TZ='Etc/UTC'
|
||||
@@ -60,7 +62,7 @@ Create ```/var/data/config/elkarbackup/elkarbackup-db-backup.env```, and populat
|
||||
|
||||
No, me either :shrug:
|
||||
|
||||
```
|
||||
```bash
|
||||
# For database backup (keep 7 days daily backups)
|
||||
MYSQL_PWD=<same as SYMFONY__DATABASE__PASSWORD above>
|
||||
MYSQL_USER=root
|
||||
@@ -175,7 +177,7 @@ From the WebUI, you can download a script intended to be executed on a remote ho
|
||||
|
||||
Here's a variation to the standard script, which I've employed:
|
||||
|
||||
```
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
REPOSITORY=/var/data/elkarbackup/backups
|
||||
@@ -229,4 +231,4 @@ This takes you to a list of backup names and file paths. You can choose to downl
|
||||
[^1]: If you wanted to expose the ElkarBackup UI directly, you could remove the oauth2_proxy from the design, and move the traefik_public-related labels directly to the app service. You'd also need to add the traefik_public network to the app service.
|
||||
[^2]: The original inclusion of ElkarBackup was due to the efforts of @gpulido in our [Discord server](http://chat.funkypenguin.co.nz). Thanks Gabriel!
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -18,7 +18,7 @@ I've started experimenting with Emby as an alternative to Plex, because of the a
|
||||
|
||||
We'll need a location to store Emby's library data, config files, logs and temporary transcoding space, so create /var/data/emby, and make sure it's owned by the user and group who also own your media data.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/emby
|
||||
```
|
||||
|
||||
@@ -26,7 +26,7 @@ mkdir /var/data/emby
|
||||
|
||||
Create emby.env, and populate with PUID/GUID for the user who owns the /var/data/emby directory (_above_) and your actual media content (_in this example, the media content is at **/srv/data**_)
|
||||
|
||||
```
|
||||
```bash
|
||||
PUID=
|
||||
GUID=
|
||||
```
|
||||
@@ -82,4 +82,4 @@ Log into your new instance at https://**YOUR-FQDN**, and complete the wizard-bas
|
||||
[^2]: Got an NVIDIA GPU? See [this blog post](https://www.funkypenguin.co.nz/note/gpu-transcoding-with-emby-plex-using-docker-nvidia/) re how to use your GPU to transcode your media!
|
||||
[^3]: We don't bother exposing the HTTPS port for Emby, since [Traefik](/ha-docker-swarm/traefik/) is doing the SSL termination for us already.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -20,7 +20,7 @@ You will be then able to interact with other people regardless of which pod they
|
||||
|
||||
First we create a directory to hold our funky data:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/funkwhale
|
||||
```
|
||||
|
||||
@@ -95,16 +95,16 @@ networks:
|
||||
|
||||
### Unleash the Whale! 🐳
|
||||
|
||||
Launch the Funkwhale stack by running `docker stack deploy funkwhale -c <path -to-docker-compose.yml>`, and then watch the container logs using `docker stack logs funkywhale_funkywhale<tab-completion-helps>`.
|
||||
Launch the Funkwhale stack by running `docker stack deploy funkwhale -c <path -to-docker-compose.yml>`, and then watch the container logs using `docker stack logs funkywhale_funkywhale<tab-completion-helps>`.
|
||||
|
||||
You'll know the container is ready when you see an ascii version of the Funkwhale logo, followed by:
|
||||
|
||||
```
|
||||
```bash
|
||||
[2021-01-27 22:52:24 +0000] [411] [INFO] ASGI 'lifespan' protocol appears unsupported.
|
||||
[2021-01-27 22:52:24 +0000] [411] [INFO] Application startup complete.
|
||||
```
|
||||
|
||||
The first time we run Funkwhale, we need to setup the superuser account.
|
||||
The first time we run Funkwhale, we need to setup the superuser account.
|
||||
|
||||
!!! tip
|
||||
If you're running a multi-node swarm, this next step needs to be executed on the node which is currently running Funkwhale. Identify this with `docker stack ps funkwhale`
|
||||
@@ -132,11 +132,10 @@ Superuser created successfully.
|
||||
root@swarm:~#
|
||||
```
|
||||
|
||||
|
||||
[^1]: Since the whole purpose of media sharing is to share **publically**, and Funkwhale includes robust user authentication, this recipe doesn't employ traefik-based authentication using [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/).
|
||||
[^2]: These instructions are an opinionated simplication of the official instructions found at https://docs.funkwhale.audio/installation/docker.html
|
||||
[^2]: These instructions are an opinionated simplication of the official instructions found at <https://docs.funkwhale.audio/installation/docker.html>
|
||||
[^3]: It should be noted that if you import your existing media, the files will be **copied** into Funkwhale's data folder. There doesn't seem to be a way to point Funkwhale at an existing collection and have it just play it from the filesystem. To this end, be prepared for double disk space usage if you plan to import your entire music collection!
|
||||
[^5]: No consideration is given at this point to backing up the Funkwhale data. Post a comment below if you'd like to see a backup container added!
|
||||
[^4]: If the funky whale is "playing your song", note that the funkwhale project is [looking for maintainers](https://blog.funkwhale.audio/~/Announcements/funkwhale-is-looking-for-new-maintainers/).
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -6,7 +6,7 @@ description: Ghost - Beautiful online publicatio (who you gonna call?)
|
||||
|
||||
[Ghost](https://ghost.org) is "a fully open source, hackable platform for building and running a modern online publication."
|
||||
|
||||

|
||||

|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
|
||||
@@ -16,7 +16,7 @@ description: Ghost - Beautiful online publicatio (who you gonna call?)
|
||||
|
||||
Create the location for the bind-mount of the application data, so that it's persistent:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/ghost
|
||||
```
|
||||
|
||||
@@ -48,7 +48,6 @@ networks:
|
||||
external: true
|
||||
```
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Launch Ghost stack
|
||||
@@ -59,4 +58,4 @@ Create your first administrative account at https://**YOUR-FQDN**/admin/
|
||||
|
||||
[^1]: A default using the SQlite database takes 548k of space
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -24,7 +24,7 @@ Existing:
|
||||
|
||||
We'll need several directories to bind-mount into our runner containers, so create them in `/var/data/gitlab`:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/gitlab/runners/{1,2}
|
||||
```
|
||||
|
||||
@@ -66,7 +66,7 @@ From your GitLab UI, you can retrieve a "token" necessary to register a new runn
|
||||
|
||||
Sample runner config.toml:
|
||||
|
||||
```
|
||||
```ini
|
||||
concurrent = 1
|
||||
check_interval = 0
|
||||
|
||||
@@ -94,5 +94,4 @@ Launch the GitLab Runner stack by running `docker stack deploy gitlab-runner -c
|
||||
[^1]: You'll note that I setup 2 runners. One is locked to a single project (_this cookbook build_), and the other is a shared runner. I wanted to ensure that one runner was always available to run CI for this project, even if I'd tied up another runner on something heavy-duty, like a container build. Customize this to your use case.
|
||||
[^2]: Originally I deployed runners in the same stack as GitLab, but I found that they would frequently fail to start properly when I launched the stack. I think that this was because the runners started so quickly (_and GitLab starts **sooo** slowly!_), that they always started up reporting that the GitLab instance was invalid or unavailable. I had issues with CI builds stuck permanently in a "pending" state, which were only resolved by restarting the runner. Having the runners deployed in a separate stack to GitLab avoids this problem.
|
||||
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,5 +1,3 @@
|
||||
hero: Gitlab - A recipe for a self-hosted GitHub alternative
|
||||
|
||||
# GitLab
|
||||
|
||||
GitLab is a self-hosted [alternative to GitHub](https://about.gitlab.com/comparison/). The most common use case is (a set of) developers with the desire for the rich feature-set of GitHub, but with unlimited private repositories.
|
||||
@@ -14,7 +12,7 @@ Docker does maintain an [official "Omnibus" container](https://docs.gitlab.com/o
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/gitlab:
|
||||
|
||||
```
|
||||
```bash
|
||||
cd /var/data
|
||||
mkdir gitlab
|
||||
cd gitlab
|
||||
@@ -27,8 +25,9 @@ You'll need to know the following:
|
||||
|
||||
1. Choose a password for postgresql, you'll need it for DB_PASS in the compose file (below)
|
||||
2. Generate 3 passwords using ```pwgen -Bsv1 64```. You'll use these for the XXX_KEY_BASE environment variables below
|
||||
2. Create gitlab.env, and populate with **at least** the following variables (the full set is available at https://github.com/sameersbn/docker-gitlab#available-configuration-parameters):
|
||||
```
|
||||
3. Create gitlab.env, and populate with **at least** the following variables (the full set is available at <https://github.com/sameersbn/docker-gitlab#available-configuration-parameters>):
|
||||
|
||||
```bash
|
||||
DB_USER=gitlab
|
||||
DB_PASS=gitlabdbpass
|
||||
DB_NAME=gitlabhq_production
|
||||
@@ -115,8 +114,8 @@ networks:
|
||||
|
||||
Launch the mail server stack by running ```docker stack deploy gitlab -c <path -to-docker-compose.yml>```
|
||||
|
||||
Log into your new instance at https://[your FQDN], with user "root" and the password you specified in gitlab.env.
|
||||
Log into your new instance at `https://[your FQDN]`, with user "root" and the password you specified in gitlab.env.
|
||||
|
||||
[^1]: I use the **sameersbn/gitlab:latest** image, rather than a specific version. This lets me execute updates simply by redeploying the stack (and why **wouldn't** I want the latest version?)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -16,7 +16,6 @@ Gollum pages:
|
||||
* Can be edited with your favourite system editor or IDE (_changes will be visible after committing_) or with the built-in web interface.
|
||||
* Can be displayed in all versions (_commits_).
|
||||
|
||||
|
||||

|
||||
|
||||
As you'll note in the (_real world_) screenshot above, my requirements for a personal wiki are:
|
||||
@@ -40,7 +39,7 @@ Gollum meets all these requirements, and as an added bonus, is extremely fast an
|
||||
|
||||
We'll need an empty git repository in /var/data/gollum for our data:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/gollum
|
||||
cd /var/data/gollum
|
||||
git init
|
||||
@@ -51,7 +50,7 @@ git init
|
||||
1. Choose an oauth provider, and obtain a client ID and secret
|
||||
2. Create gollum.env, and populate with the following variables (_you can make the cookie secret whatever you like_)
|
||||
|
||||
```
|
||||
```bash
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
OAUTH2_PROXY_COOKIE_SECRET=
|
||||
@@ -122,4 +121,4 @@ Authenticate against your OAuth provider, and then start editing your wiki!
|
||||
|
||||
[^1]: In the current implementation, Gollum is a "single user" tool only. The contents of the wiki are saved as markdown files under /var/data/gollum, and all the git commits are currently "Anonymous"
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -18,7 +18,7 @@ This recipie combines the [extensibility](https://home-assistant.io/components/)
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/homeassistant:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/homeassistant
|
||||
cd /var/data/homeassistant
|
||||
mkdir -p {homeassistant,grafana,influxdb-backup}
|
||||
@@ -26,15 +26,15 @@ mkdir -p {homeassistant,grafana,influxdb-backup}
|
||||
|
||||
Now create a directory for the influxdb realtime data:
|
||||
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/runtime/homeassistant/influxdb
|
||||
```
|
||||
|
||||
### Prepare environment
|
||||
|
||||
Create /var/data/config/homeassistant/grafana.env, and populate with the following - this is to enable grafana to work with oauth2_proxy without requiring an additional level of authentication:
|
||||
```
|
||||
|
||||
```bash
|
||||
GF_AUTH_BASIC_ENABLED=false
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
@@ -126,8 +126,8 @@ networks:
|
||||
|
||||
Launch the Home Assistant stack by running ```docker stack deploy homeassistant -c <path -to-docker-compose.yml>```
|
||||
|
||||
Log into your new instance at https://**YOUR-FQDN**, the password you created in configuration.yml as "frontend - api_key". Then setup a bunch of sensors, and log into https://grafana.**YOUR FQDN** and create some beautiful graphs :)
|
||||
Log into your new instance at https://**YOUR-FQDN**, the password you created in configuration.yml as "frontend - api_key". Then setup a bunch of sensors, and log into <https://grafana>.**YOUR FQDN** and create some beautiful graphs :)
|
||||
|
||||
[^1]: I **tried** to protect Home Assistant using [oauth2_proxy](/reference/oauth_proxy), but HA is incompatible with the websockets implementation used by Home Assistant. Until this can be fixed, I suggest that geeks set frontend: api_key to a long and complex string, and rely on this to prevent malevolent internet miscreants from turning their lights on at 2am!
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -8,7 +8,7 @@ One of the most useful features of Home Assistant is location awareness. I don't
|
||||
## Ingredients
|
||||
|
||||
1. [HomeAssistant](/recipes/homeassistant/) per recipe
|
||||
2. iBeacon(s) - This recipe is for https://s.click.aliexpress.com/e/bzyLCnAp
|
||||
2. iBeacon(s) - This recipe is for <https://s.click.aliexpress.com/e/bzyLCnAp>
|
||||
3. [LightBlue Explorer](https://itunes.apple.com/nz/app/lightblue-explorer/id557428110?mt=8)
|
||||
|
||||
## Preparation
|
||||
@@ -17,10 +17,10 @@ One of the most useful features of Home Assistant is location awareness. I don't
|
||||
|
||||
The iBeacons come with no UUID. We use the LightBlue Explorer app to pair with them (_code is "123456"_), and assign own own UUID.
|
||||
|
||||
Generate your own UUID, or get a random one at https://www.uuidgenerator.net/
|
||||
Generate your own UUID, or get a random one at <https://www.uuidgenerator.net/>
|
||||
|
||||
Plug in your iBeacon, launch LightBlue Explorer, and find your iBeacon. The first time you attempt to interrogate it, you'll be prompted to pair. Although it's not recorded anywhere in the documentation (_grr!_), the pairing code is **123456**
|
||||
|
||||
Having paired, you'll be able to see the vital statistics of your iBeacon.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -6,6 +6,7 @@ description: A self-hosted, hackable version of IFFTT / Zapier
|
||||
|
||||
Huginn is a system for building agents that perform automated tasks for you online. They can read the web, watch for events, and take actions on your behalf. Huginn's Agents create and consume events, propagating them along a directed graph. Think of it as a hackable version of IFTTT or Zapier on your own server.
|
||||
|
||||
<!-- markdownlint-disable MD033 -->
|
||||
<iframe src="https://player.vimeo.com/video/61976251" width="640" height="433" frameborder="0" webkitallowfullscreen mozallowfullscreen allowfullscreen></iframe>
|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
@@ -16,7 +17,7 @@ Huginn is a system for building agents that perform automated tasks for you onli
|
||||
|
||||
Create the location for the bind-mount of the database, so that it's persistent:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/huginn/database
|
||||
```
|
||||
|
||||
@@ -24,7 +25,7 @@ mkdir -p /var/data/huginn/database
|
||||
|
||||
Strictly speaking, you don't **have** to integrate Huginn with email. However, since we created our own mailserver stack earlier, it's worth using it to enable emails within Huginn.
|
||||
|
||||
```
|
||||
```bash
|
||||
cd /var/data/docker-mailserver/
|
||||
./setup.sh email add huginn@huginn.example.com my-password-here
|
||||
# Setup MX and DKIM if they don't already exist:
|
||||
@@ -36,7 +37,7 @@ cat config/opendkim/keys/huginn.example.com/mail.txt
|
||||
|
||||
Create /var/data/config/huginn/huginn.env, and populate with the following variables. Set the "INVITATION_CODE" variable if you want to require users to enter a code to sign up (protects the UI from abuse) (The full list of Huginn environment variables is available [here](https://github.com/huginn/huginn/blob/master/.env.example))
|
||||
|
||||
```
|
||||
```bash
|
||||
# For huginn/huginn - essential
|
||||
SMTP_DOMAIN=your-domain-here.com
|
||||
SMTP_USER_NAME=you@gmail.com
|
||||
|
||||
@@ -20,7 +20,7 @@ Great power, right? A client (_yes, you can [hire](https://www.funkypenguin.co.n
|
||||
|
||||
We need a data location to store InstaPy's config, as well as its log files. Create /var/data/instapy per below
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/instapy/logs
|
||||
```
|
||||
|
||||
@@ -65,18 +65,18 @@ services:
|
||||
|
||||
### Command your bot
|
||||
|
||||
Create a variation of https://github.com/timgrossmann/InstaPy/blob/master/docker_quickstart.py at /var/data/instapy/instapy.py (the file we bind-mounted in the swarm config above)
|
||||
Create a variation of <https://github.com/timgrossmann/InstaPy/blob/master/docker_quickstart.py> at /var/data/instapy/instapy.py (the file we bind-mounted in the swarm config above)
|
||||
|
||||
Change at least the following:
|
||||
|
||||
````
|
||||
```bash
|
||||
insta_username = ''
|
||||
insta_password = ''
|
||||
````
|
||||
```
|
||||
|
||||
Here's an example of my config, set to like a single penguin-pic per run:
|
||||
|
||||
```
|
||||
```python
|
||||
insta_username = 'funkypenguin'
|
||||
insta_password = 'followmemypersonalbrandisawesome'
|
||||
|
||||
@@ -117,6 +117,7 @@ Launch the bot by running ```docker stack deploy instapy -c <path -to-docker-com
|
||||
|
||||
While you're waiting for Docker to pull down the images, educate yourself on the risk of a robotic uprising:
|
||||
|
||||
<!-- markdownlint-disable MD033 -->
|
||||
<iframe width="560" height="315" src="https://www.youtube.com/embed/B1BdQcJ2ZYY" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
|
||||
|
||||
After swarm deploys, you won't see much, but you can monitor what InstaPy is doing, by running ```docker service logs instapy_web```.
|
||||
@@ -125,4 +126,4 @@ You can **also** watch the bot at work by VNCing to your docker swarm, password
|
||||
|
||||
[^1]: Amazingly, my bot has ended up tagging more _non-penguins_ than actual penguins. I don't understand how Instagrammers come up with their hashtags!
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
# IPFS
|
||||
|
||||
!!! danger "This recipe is a work in progress"
|
||||
This recipe is **incomplete**, and remains a work in progress.
|
||||
So... There may be errors and inaccuracies. Jump into [Discord](http://chat.funkypenguin.co.nz) if you're encountering issues 😁
|
||||
|
||||
# IPFS
|
||||
|
||||
The intention of this recipe is to provide a local IPFS cluster for the purpose of providing persistent storage for the various components of the recipes
|
||||
|
||||

|
||||
@@ -22,7 +22,7 @@ Since IPFS may _replace_ ceph or glusterfs as a shared-storage provider for the
|
||||
|
||||
On _each_ node, therefore run the following, to create the persistent data storage for ipfs and ipfs-cluster:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p {/var/ipfs/daemon,/var/ipfs/cluster}
|
||||
```
|
||||
|
||||
@@ -32,7 +32,7 @@ ipfs-cluster nodes require a common secret, a 32-bit hex-encoded string, in orde
|
||||
|
||||
Now on _each_ node, create ```/var/ipfs/cluster:/data/ipfs-cluster```, including both the secret, *and* the IP of docker0 interface on your hosts (_on my hosts, this is always 172.17.0.1_). We do this (_the trick with docker0)_ to allow ipfs-cluster to talk to the local ipfs daemon, per-node:
|
||||
|
||||
```
|
||||
```bash
|
||||
SECRET=<string generated above>
|
||||
|
||||
# Use docker0 to access daemon
|
||||
@@ -72,10 +72,9 @@ services:
|
||||
|
||||
Launch all nodes independently with ```docker-compose -f ipfs.yml up```. At this point, the nodes are each running independently, unaware of each other. But we do this to ensure that service.json is populated on each node, using the IPFS_API environment variable we specified in ipfs.env. (_it's only used on the first run_)
|
||||
|
||||
|
||||
The output looks something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
cluster_1 | 11:03:33.272 INFO restapi: REST API (libp2p-http): ENABLED. Listening on:
|
||||
cluster_1 | /ip4/127.0.0.1/tcp/9096/ipfs/QmbqPBLJNXWpbXEX6bVhYLo2ruEBE7mh1tfT9s6VXUzYYx
|
||||
cluster_1 | /ip4/172.18.0.3/tcp/9096/ipfs/QmbqPBLJNXWpbXEX6bVhYLo2ruEBE7mh1tfT9s6VXUzYYx
|
||||
@@ -101,7 +100,7 @@ Pick a node to be your primary node, and CTRL-C the others.
|
||||
|
||||
Look for a line like this in the output of the primary node:
|
||||
|
||||
```
|
||||
```bash
|
||||
/ip4/127.0.0.1/tcp/9096/ipfs/QmbqPBLJNXWpbXEX6bVhYLo2ruEBE7mh1tfT9s6VXUzYYx
|
||||
```
|
||||
|
||||
@@ -111,8 +110,7 @@ You'll note several addresses listed, all ending in the same hash. None of these
|
||||
|
||||
On each of the non-primary nodes, run the following, replacing **IP-OF-PRIMARY-NODE** with the actual IP of the primary node, and **HASHY-MC-HASHFACE** with your own hash from primary output above.
|
||||
|
||||
|
||||
```
|
||||
```bash
|
||||
docker run --rm -it -v /var/ipfs/cluster:/data/ipfs-cluster \
|
||||
--entrypoint ipfs-cluster-service ipfs/ipfs-cluster \
|
||||
daemon --bootstrap \ /ip4/IP-OF-PRIMARY-NODE/tcp/9096/ipfs/HASHY-MC-HASHFACE
|
||||
@@ -120,7 +118,7 @@ docker run --rm -it -v /var/ipfs/cluster:/data/ipfs-cluster \
|
||||
|
||||
You'll see output like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
10:55:26.121 INFO service: Bootstrapping to /ip4/192.168.31.13/tcp/9096/ipfs/QmPrmQvW5knXLBE94jzpxvdtLSwXZeFE5DSY3FuMxypDsT daemon.go:153
|
||||
10:55:26.121 INFO ipfshttp: IPFS Proxy: /ip4/0.0.0.0/tcp/9095 -> /ip4/172.17.0.1/tcp/5001 ipfshttp.go:221
|
||||
10:55:26.304 ERROR ipfshttp: error posting to IPFS: Post http://172.17.0.1:5001/api/v0/id: dial tcp 172.17.0.1:5001: connect: connection refused ipfshttp.go:708
|
||||
@@ -144,7 +142,7 @@ docker-exec into one of the cluster containers (_it doesn't matter which one_),
|
||||
|
||||
You should see output from each node member, indicating it can see its other peers. Here's my output from a 3-node cluster:
|
||||
|
||||
```
|
||||
```bash
|
||||
/ # ipfs-cluster-ctl peers ls
|
||||
QmPrmQvW5knXLBE94jzpxvdtLSwXZeFE5DSY3FuMxypDsT | ef68b1437c56 | Sees 2 other peers
|
||||
> Addresses:
|
||||
@@ -178,4 +176,4 @@ QmbqPBLJNXWpbXEX6bVhYLo2ruEBE7mh1tfT9s6VXUzYYx | 28c13ec68f33 | Sees 2 other pee
|
||||
|
||||
[^1]: I'm still trying to work out how to _mount_ the ipfs data in my filesystem in a usable way. Which is why this is still a WIP :)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -18,13 +18,13 @@ If it looks very similar as Emby, is because it started as a fork of it, but it
|
||||
|
||||
We'll need a location to store Jellyfin's library data, config files, logs and temporary transcoding space, so create ``/var/data/jellyfin``, and make sure it's owned by the user and group who also own your media data.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/jellyfin
|
||||
```
|
||||
|
||||
Also if we want to avoid the cache to be part of the backup, we should create a location to map it on the runtime folder. It also has to be owned by the user and group who also own your media data.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/runtime/jellyfin
|
||||
```
|
||||
|
||||
@@ -32,7 +32,7 @@ mkdir /var/data/runtime/jellyfin
|
||||
|
||||
Create jellyfin.env, and populate with PUID/GUID for the user who owns the /var/data/jellyfin directory (_above_) and your actual media content (_in this example, the media content is at **/srv/data**_)
|
||||
|
||||
```
|
||||
```bash
|
||||
PUID=
|
||||
GUID=
|
||||
```
|
||||
@@ -91,4 +91,4 @@ Log into your new instance at https://**YOUR-FQDN**, and complete the wizard-bas
|
||||
[^2]: Got an NVIDIA GPU? See [this blog post](https://www.funkypenguin.co.nz/note/gpu-transcoding-with-emby-plex-using-docker-nvidia/) re how to use your GPU to transcode your media!
|
||||
[^3]: We don't bother exposing the HTTPS port for Jellyfin, since [Traefik](/ha-docker-swarm/traefik/) is doing the SSL termination for us already.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -19,7 +19,7 @@ Features include:
|
||||
* Free, open source and self-hosted
|
||||
* Super simple installation
|
||||
|
||||

|
||||

|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
|
||||
@@ -29,7 +29,7 @@ Features include:
|
||||
|
||||
Create the location for the bind-mount of the application data, so that it's persistent:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/kanboard
|
||||
```
|
||||
|
||||
@@ -37,7 +37,7 @@ mkdir -p /var/data/kanboard
|
||||
|
||||
If you intend to use an [OAuth proxy](/reference/oauth_proxy/) to further secure public access to your instance, create a ```kanboard.env``` file to hold your environment variables, and populate with your OAuth provider's details (_the cookie secret you can just make up_):
|
||||
|
||||
```
|
||||
```bash
|
||||
# If you decide to protect kanboard with an oauth_proxy, complete these
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
|
||||
@@ -16,7 +16,7 @@ description: Kick-ass OIDC and identity management
|
||||
|
||||
We'll need several directories to bind-mount into our container for both runtime and backup data, so create them as follows
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/runtime/keycloak/database
|
||||
mkdir -p /var/data/keycloak/database-dump
|
||||
```
|
||||
@@ -25,7 +25,7 @@ mkdir -p /var/data/keycloak/database-dump
|
||||
|
||||
Create `/var/data/config/keycloak/keycloak.env`, and populate with the following variables, customized for your own domain structure.
|
||||
|
||||
```
|
||||
```bash
|
||||
# Technically, this could be auto-detected, but we prefer to be prescriptive
|
||||
DB_VENDOR=postgres
|
||||
DB_DATABASE=keycloak
|
||||
@@ -48,7 +48,7 @@ POSTGRES_PASSWORD=myuberpassword
|
||||
|
||||
Create `/var/data/config/keycloak/keycloak-backup.env`, and populate with the following, so that your database can be backed up to the filesystem, daily:
|
||||
|
||||
```
|
||||
```bash
|
||||
PGHOST=keycloak-db
|
||||
PGUSER=keycloak
|
||||
PGPASSWORD=myuberpassword
|
||||
@@ -128,4 +128,4 @@ Launch the KeyCloak stack by running `docker stack deploy keycloak -c <path -to-
|
||||
|
||||
Log into your new instance at https://**YOUR-FQDN**, and login with the user/password you defined in `keycloak.env`.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -55,7 +55,6 @@ For each of the following mappers, click the name, and set the "_Read Only_" fla
|
||||
|
||||

|
||||
|
||||
|
||||
## Summary
|
||||
|
||||
We've setup a new realm in KeyCloak, and configured read-write federation to an [OpenLDAP](/recipes/openldap/) backend. We can now manage our LDAP users using either KeyCloak or LDAP directly, and we can protect vulnerable services using [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/).
|
||||
@@ -65,4 +64,4 @@ We've setup a new realm in KeyCloak, and configured read-write federation to an
|
||||
|
||||
* [X] KeyCloak realm in read-write federation with [OpenLDAP](/recipes/openldap/) directory
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -37,4 +37,4 @@ We've setup users in KeyCloak, which we can now use to authenticate to KeyCloak,
|
||||
|
||||
* [X] Username / password to authenticate against [KeyCloak](/recipes/keycloak/)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -16,7 +16,7 @@ Having an authentication provider is not much use until you start authenticating
|
||||
|
||||
* [ ] The URI(s) to protect with the OIDC provider. Refer to the [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/) recipe for more information
|
||||
|
||||
## Preparation
|
||||
## Preparation
|
||||
|
||||
### Create Client
|
||||
|
||||
@@ -45,11 +45,11 @@ Now that you've changed the access type, and clicked **Save**, an additional **C
|
||||
|
||||
## Summary
|
||||
|
||||
We've setup an OIDC client in KeyCloak, which we can now use to protect vulnerable services using [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/). The OIDC URL provided by KeyCloak in the master realm, is *https://<your-keycloak-url\>/realms/master/.well-known/openid-configuration*
|
||||
We've setup an OIDC client in KeyCloak, which we can now use to protect vulnerable services using [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/). The OIDC URL provided by KeyCloak in the master realm, is `https://<your-keycloak-url>/realms/master/.well-known/openid-configuration`
|
||||
|
||||
!!! Summary
|
||||
Created:
|
||||
|
||||
* [X] Client ID and Client Secret used to authenticate against KeyCloak with OpenID Connect
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -13,7 +13,7 @@ So you've just watched a bunch of superhero movies, and you're suddenly inspired
|
||||
## Ingredients
|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
* [X] [AutoPirate](/recipes/autopirate/) components (*specifically [Mylar](/recipes/autopirate/mylar/)*), for searching for, downloading, and managing comic books
|
||||
*[X] [AutoPirate](/recipes/autopirate/) components (*specifically [Mylar](/recipes/autopirate/mylar/)*), for searching for, downloading, and managing comic books
|
||||
|
||||
## Preparation
|
||||
|
||||
@@ -21,7 +21,7 @@ So you've just watched a bunch of superhero movies, and you're suddenly inspired
|
||||
|
||||
First we create a directory to hold the komga database, logs and other persistent data:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/komga
|
||||
```
|
||||
|
||||
@@ -73,4 +73,4 @@ If Komga scratches your particular itch, please join me in [sponsoring the devel
|
||||
|
||||
[^1]: Since Komga doesn't need to communicate with any other services, we don't need a separate overlay network for it. Provided Traefik can reach Komga via the `traefik_public` overlay network, we've got all we need.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
#Kanboard
|
||||
# Kanboard
|
||||
|
||||
Kanboard is a Kanban tool, developed by [Frédéric Guillot](https://github.com/fguillot). (_Who also happens to be the developer of my favorite RSS reader, [Miniflux](/recipes/miniflux/)_)
|
||||
|
||||
@@ -28,7 +28,7 @@ Features include:
|
||||
|
||||
When you deployed [Traefik via the helm chart](/kubernetes/traefik/), you would have customized ```values.yml``` for your deployment. In ```values.yml``` is a list of namespaces which Traefik is permitted to access. Update ```values.yml``` to include the *kanboard* namespace, as illustrated below:
|
||||
|
||||
```
|
||||
```yaml
|
||||
<snip>
|
||||
kubernetes:
|
||||
namespaces:
|
||||
@@ -45,7 +45,7 @@ If you've updated ```values.yml```, upgrade your traefik deployment via helm, by
|
||||
|
||||
Although we could simply bind-mount local volumes to a local Kubuernetes cluster, since we're targetting a cloud-based Kubernetes deployment, we only need a local path to store the YAML files which define the various aspects of our Kubernetes deployment.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/config/kanboard
|
||||
```
|
||||
|
||||
@@ -53,7 +53,7 @@ mkdir /var/data/config/kanboard
|
||||
|
||||
We use Kubernetes namespaces for service discovery and isolation between our stacks, so create a namespace for the kanboard stack with the following .yml:
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/config/kanboard/namespace.yml
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
@@ -67,7 +67,7 @@ kubectl create -f /var/data/config/kanboard/namespace.yaml
|
||||
|
||||
Persistent volume claims are a streamlined way to create a persistent volume and assign it to a container in a pod. Create a claim for the kanboard app and plugin data:
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/config/kanboard/persistent-volumeclaim.yml
|
||||
kind: PersistentVolumeClaim
|
||||
apiVersion: v1
|
||||
@@ -91,14 +91,15 @@ kubectl create -f /var/data/config/kanboard/kanboard-volumeclaim.yaml
|
||||
|
||||
### Create ConfigMap
|
||||
|
||||
Kanboard's configuration is all contained within ```config.php```, which needs to be presented to the container. We _could_ maintain ```config.php``` in the persistent volume we created above, but this would require manually accessing the pod every time we wanted to make a change.
|
||||
Kanboard's configuration is all contained within ```config.php```, which needs to be presented to the container. We _could_ maintain ```config.php``` in the persistent volume we created above, but this would require manually accessing the pod every time we wanted to make a change.
|
||||
|
||||
Instead, we'll create ```config.php``` as a [ConfigMap](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/), meaning it "lives" within the Kuberetes cluster and can be **presented** to our pod. When we want to make changes, we simply update the ConfigMap (*delete and recreate, to be accurate*), and relaunch the pod.
|
||||
|
||||
Grab a copy of [config.default.php](https://github.com/kanboard/kanboard/blob/master/config.default.php), save it to ```/var/data/config/kanboard/config.php```, and customize it per [the guide](https://docs.kanboard.org/en/latest/admin_guide/config_file.html).
|
||||
|
||||
At the very least, I'd suggest making the following changes:
|
||||
```
|
||||
|
||||
```php
|
||||
define('PLUGIN_INSTALLER', true); // Yes, I want to install plugins using the UI
|
||||
define('ENABLE_URL_REWRITE', false); // Yes, I want pretty URLs
|
||||
```
|
||||
@@ -107,7 +108,7 @@ Now create the configmap from config.php, by running ```kubectl create configmap
|
||||
|
||||
## Serving
|
||||
|
||||
Now that we have a [namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/), a [persistent volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/), and a [configmap](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/), we can create a [deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/), [service](https://kubernetes.io/docs/concepts/services-networking/service/), and [ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) for the kanboard [pod](https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/).
|
||||
Now that we have a [namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/), a [persistent volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/), and a [configmap](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/), we can create a [deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/), [service](https://kubernetes.io/docs/concepts/services-networking/service/), and [ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) for the kanboard [pod](https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/).
|
||||
|
||||
### Create deployment
|
||||
|
||||
@@ -115,7 +116,7 @@ Create a deployment to tell Kubernetes about the desired state of the pod (*whic
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/kanboard/deployment.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Deployment
|
||||
@@ -160,7 +161,7 @@ kubectl create -f /var/data/kanboard/deployment.yml
|
||||
|
||||
Check that your deployment is running, with ```kubectl get pods -n kanboard```. After a minute or so, you should see a "Running" pod, as illustrated below:
|
||||
|
||||
```
|
||||
```bash
|
||||
[funkypenguin:~] % kubectl get pods -n kanboard
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
app-79f97f7db6-hsmfg 1/1 Running 0 11d
|
||||
@@ -171,7 +172,7 @@ app-79f97f7db6-hsmfg 1/1 Running 0 11d
|
||||
|
||||
The service resource "advertises" the availability of TCP port 80 in your pod, to the rest of the cluster (*constrained within your namespace*). It seems a little like overkill coming from the Docker Swarm's automated "service discovery" model, but the Kubernetes design allows for load balancing, rolling upgrades, and health checks of individual pods, without impacting the rest of the cluster elements.
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/kanboard/service.yml
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
@@ -191,7 +192,7 @@ kubectl create -f /var/data/kanboard/service.yml
|
||||
|
||||
Check that your service is deployed, with ```kubectl get services -n kanboard```. You should see something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
[funkypenguin:~] % kubectl get service -n kanboard
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
app ClusterIP None <none> 80/TCP 38d
|
||||
@@ -202,7 +203,7 @@ app ClusterIP None <none> 80/TCP 38d
|
||||
|
||||
The ingress resource tells Traefik what to forward inbound requests for *kanboard.example.com* to your service (defined above), which in turn passes the request to the "app" pod. Adjust the config below for your domain.
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/kanboard/ingress.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
@@ -225,7 +226,7 @@ kubectl create -f /var/data/kanboard/ingress.yml
|
||||
|
||||
Check that your service is deployed, with ```kubectl get ingress -n kanboard```. You should see something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
[funkypenguin:~] % kubectl get ingress -n kanboard
|
||||
NAME HOSTS ADDRESS PORTS AGE
|
||||
app kanboard.funkypenguin.co.nz 80 38d
|
||||
@@ -234,21 +235,20 @@ app kanboard.funkypenguin.co.nz 80 38d
|
||||
|
||||
### Access Kanboard
|
||||
|
||||
At this point, you should be able to access your instance on your chosen DNS name (*i.e. https://kanboard.example.com*)
|
||||
|
||||
At this point, you should be able to access your instance on your chosen DNS name (*i.e. <https://kanboard.example.com>*)
|
||||
|
||||
### Updating config.php
|
||||
|
||||
Since ```config.php``` is a ConfigMap now, to update it, make your local changes, and then delete and recreate the ConfigMap, by running:
|
||||
|
||||
```
|
||||
```bash
|
||||
kubectl delete configmap -n kanboard kanboard-config
|
||||
kubectl create configmap -n kanboard kanboard-config --from-file=config.php
|
||||
```
|
||||
|
||||
Then, in the absense of any other changes to the deployement definition, force the pod to restart by issuing a "null patch", as follows:
|
||||
|
||||
```
|
||||
```bash
|
||||
kubectl patch -n kanboard deployment app -p "{\"spec\":{\"template\":{\"metadata\":{\"labels\":{\"date\":\"`date +'%s'`\"}}}}}"
|
||||
```
|
||||
|
||||
@@ -258,4 +258,4 @@ To look at the Kanboard pod's logs, run ```kubectl logs -n kanboard <name of pod
|
||||
|
||||
[^1]: The simplest deployment of Kanboard uses the default SQLite database backend, stored on the persistent volume. You can convert this to a "real" database running MySQL or PostgreSQL, and running an an additional database pod and service. Contact me if you'd like further details ;)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
#Miniflux
|
||||
# Miniflux
|
||||
|
||||
Miniflux is a lightweight RSS reader, developed by [Frédéric Guillot](https://github.com/fguillot). (_Who also happens to be the developer of the favorite Open Source Kanban app, [Kanboard](/recipes/kanboard/)_)
|
||||
|
||||
@@ -14,7 +14,6 @@ I've [reviewed Miniflux in detail on my blog](https://www.funkypenguin.co.nz/rev
|
||||
!!! abstract "2.0+ is a bit different"
|
||||
[Some things changed](https://docs.miniflux.net/en/latest/migration.html) when Miniflux 2.0 was released. For one thing, the only supported database is now postgresql (_no more SQLite_). External themes are gone, as is PHP (_in favor of golang_). It's been a controversial change, but I'm keen on minimal and single-purpose, so I'm still very happy with the direction of development. The developer has laid out his [opinions](https://docs.miniflux.net/en/latest/opinionated.html) re the decisions he's made in the course of development.
|
||||
|
||||
|
||||
## Ingredients
|
||||
|
||||
1. A [Kubernetes Cluster](/kubernetes/design/) including [Traefik Ingress](/kubernetes/traefik/)
|
||||
@@ -26,7 +25,7 @@ I've [reviewed Miniflux in detail on my blog](https://www.funkypenguin.co.nz/rev
|
||||
|
||||
When you deployed [Traefik via the helm chart](/kubernetes/traefik/), you would have customized ```values.yml``` for your deployment. In ```values.yml``` is a list of namespaces which Traefik is permitted to access. Update ```values.yml``` to include the *miniflux* namespace, as illustrated below:
|
||||
|
||||
```
|
||||
```yaml
|
||||
<snip>
|
||||
kubernetes:
|
||||
namespaces:
|
||||
@@ -43,7 +42,7 @@ If you've updated ```values.yml```, upgrade your traefik deployment via helm, by
|
||||
|
||||
Although we could simply bind-mount local volumes to a local Kubuernetes cluster, since we're targetting a cloud-based Kubernetes deployment, we only need a local path to store the YAML files which define the various aspects of our Kubernetes deployment.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/config/miniflux
|
||||
```
|
||||
|
||||
@@ -51,7 +50,7 @@ mkdir /var/data/config/miniflux
|
||||
|
||||
We use Kubernetes namespaces for service discovery and isolation between our stacks, so create a namespace for the miniflux stack with the following .yml:
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/config/miniflux/namespace.yml
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
@@ -65,7 +64,7 @@ kubectl create -f /var/data/config/miniflux/namespace.yaml
|
||||
|
||||
Persistent volume claims are a streamlined way to create a persistent volume and assign it to a container in a pod. Create a claim for the miniflux postgres database:
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/config/miniflux/db-persistent-volumeclaim.yml
|
||||
kkind: PersistentVolumeClaim
|
||||
apiVersion: v1
|
||||
@@ -91,7 +90,7 @@ kubectl create -f /var/data/config/miniflux/db-persistent-volumeclaim.yaml
|
||||
|
||||
It's not always desirable to have sensitive data stored in your .yml files. Maybe you want to check your config into a git repository, or share it. Using Kubernetes Secrets means that you can create "secrets", and use these in your deployments by name, without exposing their contents. Run the following, replacing ```imtoosexyformyadminpassword```, and the ```mydbpass``` value in both postgress-password.secret **and** database-url.secret:
|
||||
|
||||
```
|
||||
```bash
|
||||
echo -n "imtoosexyformyadminpassword" > admin-password.secret
|
||||
echo -n "mydbpass" > postgres-password.secret
|
||||
echo -n "postgres://miniflux:mydbpass@db/miniflux?sslmode=disable" > database-url.secret
|
||||
@@ -105,10 +104,9 @@ kubectl create secret -n mqtt generic miniflux-credentials \
|
||||
!!! tip "Why use ```echo -n```?"
|
||||
Because. See [my blog post here](https://www.funkypenguin.co.nz/beware-the-hidden-newlines-in-kubernetes-secrets/) for the pain of hunting invisible newlines, that's why!
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
Now that we have a [namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/), a [persistent volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/), and a [configmap](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/), we can create [deployments](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/), [services](https://kubernetes.io/docs/concepts/services-networking/service/), and an [ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) for the miniflux [pods](https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/).
|
||||
Now that we have a [namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/), a [persistent volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/), and a [configmap](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/), we can create [deployments](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/), [services](https://kubernetes.io/docs/concepts/services-networking/service/), and an [ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) for the miniflux [pods](https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/).
|
||||
|
||||
### Create db deployment
|
||||
|
||||
@@ -116,7 +114,7 @@ Deployments tell Kubernetes about the desired state of the pod (*which it will t
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/miniflux/db-deployment.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Deployment
|
||||
@@ -159,7 +157,7 @@ spec:
|
||||
|
||||
Create the app deployment by excecuting the following. Again, note that the deployment refers to the secrets created above.
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/miniflux/app-deployment.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Deployment
|
||||
@@ -207,7 +205,7 @@ kubectl create -f /var/data/miniflux/deployment.yml
|
||||
|
||||
Check that your deployment is running, with ```kubectl get pods -n miniflux```. After a minute or so, you should see 2 "Running" pods, as illustrated below:
|
||||
|
||||
```
|
||||
```bash
|
||||
[funkypenguin:~] % kubectl get pods -n miniflux
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
app-667c667b75-5jjm9 1/1 Running 0 4d
|
||||
@@ -219,7 +217,7 @@ db-fcd47b88f-9vvqt 1/1 Running 0 4d
|
||||
|
||||
The db service resource "advertises" the availability of PostgreSQL's port (TCP 5432) in your pod, to the rest of the cluster (*constrained within your namespace*). It seems a little like overkill coming from the Docker Swarm's automated "service discovery" model, but the Kubernetes design allows for load balancing, rolling upgrades, and health checks of individual pods, without impacting the rest of the cluster elements.
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/miniflux/db-service.yml
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
@@ -241,8 +239,7 @@ kubectl create -f /var/data/miniflux/service.yml
|
||||
|
||||
The app service resource "advertises" the availability of miniflux's HTTP listener port (TCP 8080) in your pod. This is the service which will be referred to by the ingress (below), so that Traefik can route incoming traffic to the miniflux app.
|
||||
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/miniflux/app-service.yml
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
@@ -264,7 +261,7 @@ kubectl create -f /var/data/miniflux/app-service.yml
|
||||
|
||||
Check that your services are deployed, with ```kubectl get services -n miniflux```. You should see something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
[funkypenguin:~] % kubectl get services -n miniflux
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
app ClusterIP None <none> 8080/TCP 55d
|
||||
@@ -276,7 +273,7 @@ db ClusterIP None <none> 5432/TCP 55d
|
||||
|
||||
The ingress resource tells Traefik what to forward inbound requests for *miniflux.example.com* to your service (defined above), which in turn passes the request to the "app" pod. Adjust the config below for your domain.
|
||||
|
||||
```
|
||||
```bash
|
||||
cat <<EOF > /var/data/miniflux/ingress.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
@@ -299,7 +296,7 @@ kubectl create -f /var/data/miniflux/ingress.yml
|
||||
|
||||
Check that your service is deployed, with ```kubectl get ingress -n miniflux```. You should see something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
[funkypenguin:~] 130 % kubectl get ingress -n miniflux
|
||||
NAME HOSTS ADDRESS PORTS AGE
|
||||
app miniflux.funkypenguin.co.nz 80 55d
|
||||
@@ -308,11 +305,10 @@ app miniflux.funkypenguin.co.nz 80 55d
|
||||
|
||||
### Access Miniflux
|
||||
|
||||
At this point, you should be able to access your instance on your chosen DNS name (*i.e. https://miniflux.example.com*)
|
||||
|
||||
At this point, you should be able to access your instance on your chosen DNS name (*i.e. <https://miniflux.example.com>*)
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
To look at the Miniflux pod's logs, run ```kubectl logs -n miniflux <name of pod per above> -f```. For further troubleshooting hints, see [Troubleshooting](/reference/kubernetes/troubleshooting/).
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,262 +0,0 @@
|
||||
#Kanboard
|
||||
|
||||
Kanboard is a Kanban tool, developed by [Frédéric Guillot](https://github.com/fguillot). (_Who also happens to be the developer of my favorite RSS reader, [Miniflux](/recipes/miniflux/)_)
|
||||
|
||||

|
||||
|
||||
!!! tip "Sponsored Project"
|
||||
Kanboard is one of my [sponsored projects](/#sponsored-projects) - a project I financially support on a regular basis because of its utility to me. I use it both in my DayJob(tm), and to manage my overflowing, overly-optimistic personal commitments! 😓
|
||||
|
||||
Features include:
|
||||
|
||||
* Visualize your work
|
||||
* Limit your work in progress to be more efficient
|
||||
* Customize your boards according to your business activities
|
||||
* Multiple projects with the ability to drag and drop tasks
|
||||
* Reports and analytics
|
||||
* Fast and simple to use
|
||||
* Access from anywhere with a modern browser
|
||||
* Plugins and integrations with external services
|
||||
* Free, open source and self-hosted
|
||||
* Super simple installation
|
||||
|
||||
## Ingredients
|
||||
|
||||
1. A [Kubernetes Cluster](/kubernetes/design/) including [Traefik Ingress](/kubernetes/traefik/)
|
||||
2. A DNS name for your kanboard instance (*kanboard.example.com*, below) pointing to your [load balancer](/kubernetes/loadbalancer/), fronting your Traefik ingress
|
||||
|
||||
## Preparation
|
||||
|
||||
### Prepare traefik for namespace
|
||||
|
||||
When you deployed [Traefik via the helm chart](/kubernetes/traefik/), you would have customized ```values.yml``` for your deployment. In ```values.yml``` is a list of namespaces which Traefik is permitted to access. Update ```values.yml``` to include the *kanboard* namespace, as illustrated below:
|
||||
|
||||
```
|
||||
<snip>
|
||||
kubernetes:
|
||||
namespaces:
|
||||
- kube-system
|
||||
- nextcloud
|
||||
- kanboard
|
||||
- miniflux
|
||||
<snip>
|
||||
```
|
||||
|
||||
If you've updated ```values.yml```, upgrade your traefik deployment via helm, by running ```helm upgrade --values values.yml traefik stable/traefik --recreate-pods```
|
||||
|
||||
### Create data locations
|
||||
|
||||
Although we could simply bind-mount local volumes to a local Kubuernetes cluster, since we're targetting a cloud-based Kubernetes deployment, we only need a local path to store the YAML files which define the various aspects of our Kubernetes deployment.
|
||||
|
||||
```
|
||||
mkdir /var/data/config/kanboard
|
||||
```
|
||||
|
||||
### Create namespace
|
||||
|
||||
We use Kubernetes namespaces for service discovery and isolation between our stacks, so create a namespace for the kanboard stack with the following .yml:
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/config/kanboard/namespace.yml
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: kanboard
|
||||
EOF
|
||||
kubectl create -f /var/data/config/kanboard/namespace.yaml
|
||||
```
|
||||
|
||||
### Create persistent volume claim
|
||||
|
||||
Persistent volume claims are a streamlined way to create a persistent volume and assign it to a container in a pod. Create a claim for the kanboard app and plugin data:
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/config/kanboard/persistent-volumeclaim.yml
|
||||
kind: PersistentVolumeClaim
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: kanboard-volumeclaim
|
||||
namespace: kanboard
|
||||
annotations:
|
||||
backup.kubernetes.io/deltas: P1D P7D
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi
|
||||
EOF
|
||||
kubectl create -f /var/data/config/kanboard/kanboard-volumeclaim.yaml
|
||||
```
|
||||
|
||||
!!! question "What's that annotation about?"
|
||||
The annotation is used by [k8s-snapshots](/kubernetes/snapshots/) to create daily incremental snapshots of your persistent volumes. In this case, our volume is snapshotted daily, and copies kept for 7 days.
|
||||
|
||||
### Create ConfigMap
|
||||
|
||||
Kanboard's configuration is all contained within ```config.php```, which needs to be presented to the container. We _could_ maintain ```config.php``` in the persistent volume we created above, but this would require manually accessing the pod every time we wanted to make a change.
|
||||
|
||||
Instead, we'll create ```config.php``` as a [ConfigMap](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/), meaning it "lives" within the Kuberetes cluster and can be **presented** to our pod. When we want to make changes, we simply update the ConfigMap (*delete and recreate, to be accurate*), and relaunch the pod.
|
||||
|
||||
Grab a copy of [config.default.php](https://github.com/kanboard/kanboard/blob/master/config.default.php), save it to ```/var/data/config/kanboard/config.php```, and customize it per [the guide](https://docs.kanboard.org/en/latest/admin_guide/config_file.html).
|
||||
|
||||
At the very least, I'd suggest making the following changes:
|
||||
```
|
||||
define('PLUGIN_INSTALLER', true); // Yes, I want to install plugins using the UI
|
||||
define('ENABLE_URL_REWRITE', false); // Yes, I want pretty URLs
|
||||
```
|
||||
|
||||
Now create the configmap from config.php, by running ```kubectl create configmap -n kanboard kanboard-config --from-file=config.php```
|
||||
|
||||
## Serving
|
||||
|
||||
Now that we have a [namespace](https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/), a [persistent volume](https://kubernetes.io/docs/concepts/storage/persistent-volumes/), and a [configmap](https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/), we can create a [deployment](https://kubernetes.io/docs/concepts/workloads/controllers/deployment/), [service](https://kubernetes.io/docs/concepts/services-networking/service/), and [ingress](https://kubernetes.io/docs/concepts/services-networking/ingress/) for the kanboard [pod](https://kubernetes.io/docs/concepts/workloads/pods/pod-overview/).
|
||||
|
||||
### Create deployment
|
||||
|
||||
Create a deployment to tell Kubernetes about the desired state of the pod (*which it will then attempt to maintain*). Note below that we mount the persistent volume **twice**, to both ```/var/www/app/data``` and ```/var/www/app/plugins```, using the subPath value to differentiate them. This trick avoids us having to provision **two** persistent volumes just for data mounted in 2 separate locations.
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/kanboard/deployment.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
namespace: kanboard
|
||||
name: app
|
||||
labels:
|
||||
app: app
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: app
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: app
|
||||
spec:
|
||||
containers:
|
||||
- image: kanboard/kanboard
|
||||
name: app
|
||||
volumeMounts:
|
||||
- name: kanboard-config
|
||||
mountPath: /var/www/app/config.php
|
||||
subPath: config.php
|
||||
- name: kanboard-app
|
||||
mountPath: /var/www/app/data
|
||||
subPath: data
|
||||
- name: kanboard-app
|
||||
mountPath: /var/www/app/plugins
|
||||
subPath: plugins
|
||||
volumes:
|
||||
- name: kanboard-app
|
||||
persistentVolumeClaim:
|
||||
claimName: kanboard-app
|
||||
- name: kanboard-config
|
||||
configMap:
|
||||
name: kanboard-config
|
||||
EOF
|
||||
kubectl create -f /var/data/kanboard/deployment.yml
|
||||
```
|
||||
|
||||
Check that your deployment is running, with ```kubectl get pods -n kanboard```. After a minute or so, you should see a "Running" pod, as illustrated below:
|
||||
|
||||
```
|
||||
[funkypenguin:~] % kubectl get pods -n kanboard
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
app-79f97f7db6-hsmfg 1/1 Running 0 11d
|
||||
[funkypenguin:~] %
|
||||
```
|
||||
|
||||
### Create service
|
||||
|
||||
The service resource "advertises" the availability of TCP port 80 in your pod, to the rest of the cluster (*constrained within your namespace*). It seems a little like overkill coming from the Docker Swarm's automated "service discovery" model, but the Kubernetes design allows for load balancing, rolling upgrades, and health checks of individual pods, without impacting the rest of the cluster elements.
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/kanboard/service.yml
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: app
|
||||
namespace: kanboard
|
||||
spec:
|
||||
selector:
|
||||
app: app
|
||||
ports:
|
||||
- protocol: TCP
|
||||
port: 80
|
||||
clusterIP: None
|
||||
EOF
|
||||
kubectl create -f /var/data/kanboard/service.yml
|
||||
```
|
||||
|
||||
Check that your service is deployed, with ```kubectl get services -n kanboard```. You should see something like this:
|
||||
|
||||
```
|
||||
[funkypenguin:~] % kubectl get service -n kanboard
|
||||
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
|
||||
app ClusterIP None <none> 80/TCP 38d
|
||||
[funkypenguin:~] %
|
||||
```
|
||||
|
||||
### Create ingress
|
||||
|
||||
The ingress resource tells Traefik what to forward inbound requests for *kanboard.example.com* to your service (defined above), which in turn passes the request to the "app" pod. Adjust the config below for your domain.
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/kanboard/ingress.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Ingress
|
||||
metadata:
|
||||
name: app
|
||||
namespace: kanboard
|
||||
annotations:
|
||||
kubernetes.io/ingress.class: traefik
|
||||
spec:
|
||||
rules:
|
||||
- host: kanboard.example.com
|
||||
http:
|
||||
paths:
|
||||
- backend:
|
||||
serviceName: app
|
||||
servicePort: 80
|
||||
EOF
|
||||
kubectl create -f /var/data/kanboard/ingress.yml
|
||||
```
|
||||
|
||||
Check that your service is deployed, with ```kubectl get ingress -n kanboard```. You should see something like this:
|
||||
|
||||
```
|
||||
[funkypenguin:~] % kubectl get ingress -n kanboard
|
||||
NAME HOSTS ADDRESS PORTS AGE
|
||||
app kanboard.funkypenguin.co.nz 80 38d
|
||||
[funkypenguin:~] %
|
||||
```
|
||||
|
||||
### Access Kanboard
|
||||
|
||||
At this point, you should be able to access your instance on your chosen DNS name (*i.e. https://kanboard.example.com*)
|
||||
|
||||
|
||||
### Updating config.php
|
||||
|
||||
Since ```config.php``` is a ConfigMap now, to update it, make your local changes, and then delete and recreate the ConfigMap, by running:
|
||||
|
||||
```
|
||||
kubectl delete configmap -n kanboard kanboard-config
|
||||
kubectl create configmap -n kanboard kanboard-config --from-file=config.php
|
||||
```
|
||||
|
||||
Then, in the absense of any other changes to the deployement definition, force the pod to restart by issuing a "null patch", as follows:
|
||||
|
||||
```
|
||||
kubectl patch -n kanboard deployment app -p "{\"spec\":{\"template\":{\"metadata\":{\"labels\":{\"date\":\"`date +'%s'`\"}}}}}"
|
||||
```
|
||||
|
||||
### Troubleshooting
|
||||
|
||||
To look at the Kanboard pod's logs, run ```kubectl logs -n kanboard <name of pod per above> -f```. For further troubleshooting hints, see [Troubleshooting](/reference/kubernetes/troubleshooting/).
|
||||
|
||||
[^1]: The simplest deployment of Kanboard uses the default SQLite database backend, stored on the persistent volume. You can convert this to a "real" database running MySQL or PostgreSQL, and running an an additional database pod and service. Contact me if you'd like further details ;)
|
||||
@@ -4,7 +4,7 @@ description: Quickly share self-destructing screenshots, text, etc
|
||||
|
||||
# Linx
|
||||
|
||||
Ever wanted to quickly share a screenshot, but don't want to use imgur, sign up for a service, or have your image tracked across the internet for all time?
|
||||
Ever wanted to quickly share a screenshot, but don't want to use imgur, sign up for a service, or have your image tracked across the internet for all time?
|
||||
|
||||
Want to privately share some log output with a password, or a self-destructing cat picture?
|
||||
|
||||
@@ -26,7 +26,7 @@ Want to privately share some log output with a password, or a self-destructing c
|
||||
|
||||
First we create a directory to hold the data which linx will serve:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/linx
|
||||
```
|
||||
|
||||
@@ -34,7 +34,7 @@ mkdir /var/data/linx
|
||||
|
||||
Linx is configured using a flat text file, so create this on the Docker host, and then we'll mount it (*read-only*) into the container, below.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/config/linx
|
||||
cat << EOF > /var/data/config/linx/linx.conf
|
||||
# Refer to https://github.com/andreimarcu/linx-server for details
|
||||
@@ -87,7 +87,6 @@ networks:
|
||||
|
||||
Launch the Linx stack by running ```docker stack deploy linx -c <path -to-docker-compose.yml>```
|
||||
|
||||
|
||||
[^1]: Since the whole purpose of media/file sharing is to share stuff with **strangers**, this recipe doesn't take into account any sort of authentication using [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/).
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
+12
-12
@@ -26,7 +26,7 @@ docker-mailserver doesn't include a webmail client, and one is not strictly need
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/docker-mailserver:
|
||||
|
||||
```
|
||||
```bash
|
||||
cd /var/data
|
||||
mkdir docker-mailserver
|
||||
cd docker-mailserver
|
||||
@@ -41,7 +41,7 @@ The docker-mailserver container can _renew_ our LetsEncrypt certs for us, but it
|
||||
|
||||
In the example below, since I'm already using Traefik to manage the LE certs for my web platforms, I opted to use the DNS challenge to prove my ownership of the domain. The certbot client will prompt you to add a DNS record for domain verification.
|
||||
|
||||
```
|
||||
```bash
|
||||
docker run -ti --rm -v \
|
||||
"$(pwd)"/letsencrypt:/etc/letsencrypt certbot/certbot \
|
||||
--manual --preferred-challenges dns certonly \
|
||||
@@ -52,11 +52,12 @@ docker run -ti --rm -v \
|
||||
|
||||
docker-mailserver comes with a handy bash script for managing the stack (which is just really a wrapper around the container.) It'll make our setup easier, so download it into the root of your configuration/data directory, and make it executable:
|
||||
|
||||
```
|
||||
```bash
|
||||
curl -o setup.sh \
|
||||
https://raw.githubusercontent.com/tomav/docker-mailserver/master/setup.sh \
|
||||
chmod a+x ./setup.sh
|
||||
```
|
||||
|
||||
### Create email accounts
|
||||
|
||||
For every email address required, run ```./setup.sh email add <email> <password>``` to create the account. The command returns no output.
|
||||
@@ -69,7 +70,7 @@ Run ```./setup.sh config dkim``` to create the necessary DKIM entries. The comma
|
||||
|
||||
Examine the keys created by opendkim to identify the DNS TXT records required:
|
||||
|
||||
```
|
||||
```bash
|
||||
for i in `find config/opendkim/keys/ -name mail.txt`; do \
|
||||
echo $i; \
|
||||
cat $i; \
|
||||
@@ -78,16 +79,16 @@ done
|
||||
|
||||
You'll end up with something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
config/opendkim/keys/gitlab.example.com/mail.txt
|
||||
mail._domainkey IN TXT ( "v=DKIM1; k=rsa; "
|
||||
"p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCYuQqDg2ZG8ZOfI1PvarF1Gcr5cJnCR8BeCj5HYgeRohSrxKL5utPEF/AWAxXYwnKpgYN837fu74GfqsIuOhu70lPhGV+O2gFVgpXYWHELvIiTqqO0QgarIN63WE2gzE4s0FckfLrMuxMoXr882wuzuJhXywGxOavybmjpnNHhbQIDAQAB" ) ; ----- DKIM key mail for gitlab.example.com
|
||||
mail._domainkey IN TXT ( "v=DKIM1; k=rsa; "
|
||||
"p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCYuQqDg2ZG8ZOfI1PvarF1Gcr5cJnCR8BeCj5HYgeRohSrxKL5utPEF/AWAxXYwnKpgYN837fu74GfqsIuOhu70lPhGV+O2gFVgpXYWHELvIiTqqO0QgarIN63WE2gzE4s0FckfLrMuxMoXr882wuzuJhXywGxOavybmjpnNHhbQIDAQAB" ) ; ----- DKIM key mail for gitlab.example.com
|
||||
[root@ds1 mail]#
|
||||
```
|
||||
|
||||
Create the necessary DNS TXT entries for your domain(s). Note that although opendkim splits the record across two lines, the actual record should be concatenated on creation. I.e., the DNS TXT record above should read:
|
||||
|
||||
```
|
||||
```bash
|
||||
"v=DKIM1; k=rsa; p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQCYuQqDg2ZG8ZOfI1PvarF1Gcr5cJnCR8BeCj5HYgeRohSrxKL5utPEF/AWAxXYwnKpgYN837fu74GfqsIuOhu70lPhGV+O2gFVgpXYWHELvIiTqqO0QgarIN63WE2gzE4s0FckfLrMuxMoXr882wuzuJhXywGxOavybmjpnNHhbQIDAQAB"
|
||||
```
|
||||
|
||||
@@ -131,7 +132,7 @@ services:
|
||||
deploy:
|
||||
replicas: 1
|
||||
|
||||
rainloop:
|
||||
rainloop:
|
||||
image: hardware/rainloop
|
||||
networks:
|
||||
- internal
|
||||
@@ -158,7 +159,7 @@ networks:
|
||||
|
||||
A sample docker-mailserver.env file looks like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
ENABLE_SPAMASSASSIN=1
|
||||
ENABLE_CLAMAV=1
|
||||
ENABLE_POSTGREY=1
|
||||
@@ -170,7 +171,6 @@ PERMIT_DOCKER=network
|
||||
SSL_TYPE=letsencrypt
|
||||
```
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Launch mailserver
|
||||
@@ -181,4 +181,4 @@ Launch the mail server stack by running ```docker stack deploy docker-mailserver
|
||||
|
||||
[^2]: If you're using sieve with Rainloop, take note of the [workaround](https://discourse.geek-kitchen.funkypenguin.co.nz/t/mail-server-funky-penguins-geek-cookbook/70/15) identified by [ggilley](https://discourse.geek-kitchen.funkypenguin.co.nz/u/ggilley)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,110 +0,0 @@
|
||||
# MatterMost
|
||||
|
||||
Intro
|
||||
|
||||

|
||||
|
||||
Details
|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
|
||||
## Preparation
|
||||
|
||||
### Setup data locations
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/mattermost:
|
||||
|
||||
```
|
||||
mkdir -p /var/data/mattermost/{cert,config,data,logs,plugins,database-dump}
|
||||
mkdir -p /var/data/runtime/mattermost/database
|
||||
```
|
||||
|
||||
### Prepare environment
|
||||
|
||||
Create mattermost.env, and populate with the following variables
|
||||
```
|
||||
POSTGRES_USER=mmuser
|
||||
POSTGRES_PASSWORD=mmuser_password
|
||||
POSTGRES_DB=mattermost
|
||||
MM_USERNAME=mmuser
|
||||
MM_PASSWORD=mmuser_password
|
||||
MM_DBNAME=mattermost
|
||||
```
|
||||
|
||||
Now create mattermost-backup.env, and populate with the following variables:
|
||||
```
|
||||
PGHOST=db
|
||||
PGUSER=mmuser
|
||||
PGPASSWORD=mmuser_password
|
||||
BACKUP_NUM_KEEP=7
|
||||
BACKUP_FREQUENCY=1d
|
||||
```
|
||||
|
||||
### Setup Docker Swarm
|
||||
|
||||
Create a docker swarm config file in docker-compose syntax (v3), something like this:
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
|
||||
```yaml
|
||||
version: '3'
|
||||
|
||||
services:
|
||||
|
||||
db:
|
||||
image: mattermost/mattermost-prod-db
|
||||
env_file: /var/data/config/mattermost/mattermost.env
|
||||
volumes:
|
||||
- /var/data/runtime/mattermost/database:/var/lib/postgresql/data
|
||||
networks:
|
||||
- internal
|
||||
|
||||
app:
|
||||
image: mattermost/mattermost-team-edition
|
||||
env_file: /var/data/config/mattermost/mattermost.env
|
||||
volumes:
|
||||
- /var/data/mattermost/config:/mattermost/config:rw
|
||||
- /var/data/mattermost/data:/mattermost/data:rw
|
||||
- /var/data/mattermost/logs:/mattermost/logs:rw
|
||||
- /var/data/mattermost/plugins:/mattermost/plugins:rw
|
||||
|
||||
db-backup:
|
||||
image: mattermost/mattermost-prod-db
|
||||
env_file: /var/data/config/mattermost/mattermost-backup.env
|
||||
volumes:
|
||||
- /var/data/mattermost/database-dump:/dump
|
||||
entrypoint: |
|
||||
bash -c 'bash -s <<EOF
|
||||
trap "break;exit" SIGHUP SIGINT SIGTERM
|
||||
sleep 2m
|
||||
while /bin/true; do
|
||||
pg_dump -Fc > /dump/dump_\`date +%d-%m-%Y"_"%H_%M_%S\`.psql
|
||||
(ls -t /dump/dump*.psql|head -n $$BACKUP_NUM_KEEP;ls /dump/dump*.psql)|sort|uniq -u|xargs rm -- {}
|
||||
sleep $$BACKUP_FREQUENCY
|
||||
done
|
||||
EOF'
|
||||
networks:
|
||||
- internal
|
||||
|
||||
|
||||
networks:
|
||||
traefik_public:
|
||||
external: true
|
||||
internal:
|
||||
driver: overlay
|
||||
ipam:
|
||||
config:
|
||||
- subnet: 172.16.40.0/24
|
||||
```
|
||||
|
||||
--8<-- "reference-networks.md"
|
||||
|
||||
## Serving
|
||||
|
||||
### Launch MatterMost stack
|
||||
|
||||
Launch the MatterMost stack by running ```docker stack deploy mattermost -c <path -to-docker-compose.yml>```
|
||||
|
||||
Log into your new instance at https://**YOUR-FQDN**, with user "root" and the password you specified in mattermost.env.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
@@ -10,10 +10,10 @@ Easily add recipes into your database by providing the url[^penguinfood], and me
|
||||
|
||||

|
||||
|
||||
Mealie also provides a secure API for interactions from 3rd party applications.
|
||||
Mealie also provides a secure API for interactions from 3rd party applications.
|
||||
|
||||
!!! question "Why does my recipe manager need an API?"
|
||||
An API allows integration into applications like Home Assistant that can act as notification engines to provide custom notifications based of Meal Plan data to remind you to defrost the chicken, marinade the steak, or start the CrockPot. See the [official docs](https://hay-kot.github.io/mealie/) for more information. Additionally, you can access any available API from the backend server. To explore the API spin up your server and navigate to http://yourserver.com/docs for interactive API documentation.
|
||||
An API allows integration into applications like Home Assistant that can act as notification engines to provide custom notifications based of Meal Plan data to remind you to defrost the chicken, marinade the steak, or start the CrockPot. See the [official docs](https://hay-kot.github.io/mealie/) for more information. Additionally, you can access any available API from the backend server. To explore the API spin up your server and navigate to <http://yourserver.com/docs> for interactive API documentation.
|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
|
||||
@@ -23,7 +23,7 @@ Mealie also provides a secure API for interactions from 3rd party applications.
|
||||
|
||||
First we create a directory to hold the data which mealie will serve:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/mealie
|
||||
```
|
||||
|
||||
@@ -31,7 +31,7 @@ mkdir /var/data/mealie
|
||||
|
||||
There's only one environment variable currently required (`db_type`), but let's create an `.env` file anyway, to keep the recipe consistent and extensible.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/config/mealie
|
||||
cat << EOF > /var/data/config/mealie/mealie.env
|
||||
db_type=sqlite
|
||||
@@ -89,8 +89,8 @@ Launch the mealie stack by running ```docker stack deploy mealie -c <path -to-do
|
||||
|
||||

|
||||
|
||||
[^penguinfood]: I scraped all these recipes from https://www.food.com/search/penguin
|
||||
[^penguinfood]: I scraped all these recipes from <https://www.food.com/search/penguin>
|
||||
[^1]: If you plan to use Mealie for fancy things like an early-morning alarm to defrost the chicken, you may need to customize the [Traefik Forward Auth][tfa] rules, or even remove them entirely, for unauthenticated API access.
|
||||
[^2]: If you think Mealie is tasty, encourage the developer :cook: to keep on cookin', by [sponsoring him](https://github.com/sponsors/hay-kot) :heart:
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -26,7 +26,7 @@ I've [reviewed Miniflux in detail on my blog](https://www.funkypenguin.co.nz/rev
|
||||
|
||||
Create the location for the bind-mount of the application data, so that it's persistent:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir -p /var/data/miniflux/database-dump
|
||||
mkdir -p /var/data/runtime/miniflux/database
|
||||
|
||||
@@ -36,7 +36,7 @@ mkdir -p /var/data/runtime/miniflux/database
|
||||
|
||||
Create ```/var/data/config/miniflux/miniflux.env``` something like this:
|
||||
|
||||
```
|
||||
```bash
|
||||
DATABASE_URL=postgres://miniflux:secret@miniflux-db/miniflux?sslmode=disable
|
||||
POSTGRES_USER=miniflux
|
||||
POSTGRES_PASSWORD=secret
|
||||
@@ -52,7 +52,7 @@ ADMIN_PASSWORD=test1234
|
||||
|
||||
Create ```/var/data/config/miniflux/miniflux-backup.env```, and populate with the following, so that your database can be backed up to the filesystem, daily:
|
||||
|
||||
```
|
||||
```env
|
||||
PGHOST=miniflux-db
|
||||
PGUSER=miniflux
|
||||
PGPASSWORD=secret
|
||||
@@ -124,7 +124,6 @@ networks:
|
||||
- subnet: 172.16.22.0/24
|
||||
```
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Launch Miniflux stack
|
||||
@@ -135,4 +134,4 @@ Log into your new instance at https://**YOUR-FQDN**, using the credentials you s
|
||||
|
||||
[^1]: Find the bookmarklet under the **Settings -> Integration** page.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
+12
-11
@@ -27,7 +27,7 @@ Possible use-cases:
|
||||
|
||||
We'll need a directory to hold our minio file store, as well as our minio client config, so create a structure at /var/data/minio:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/minio
|
||||
cd /var/data/minio
|
||||
mkdir -p {mc,data}
|
||||
@@ -36,7 +36,8 @@ mkdir -p {mc,data}
|
||||
### Prepare environment
|
||||
|
||||
Create minio.env, and populate with the following variables
|
||||
```
|
||||
|
||||
```bash
|
||||
MINIO_ACCESS_KEY=<some random, complex string>
|
||||
MINIO_SECRET_KEY=<another random, complex string>
|
||||
```
|
||||
@@ -89,13 +90,13 @@ To administer the Minio server, we need the Minio client. While it's possible to
|
||||
|
||||
I created an alias on my docker nodes, allowing me to run mc quickly:
|
||||
|
||||
```
|
||||
```bash
|
||||
alias mc='docker run -it -v /docker/minio/mc/:/root/.mc/ --network traefik_public minio/mc'
|
||||
```
|
||||
|
||||
Now I use the alias to launch the client shell, and connect to my minio instance (_I could also use the external, traefik-provided URL_)
|
||||
|
||||
```
|
||||
```bash
|
||||
root@ds1:~# mc config host add minio http://app:9000 admin iambatman
|
||||
mc: Configuration written to `/root/.mc/config.json`. Please update your access credentials.
|
||||
mc: Successfully created `/root/.mc/share`.
|
||||
@@ -107,11 +108,11 @@ root@ds1:~#
|
||||
|
||||
### Add (readonly) user
|
||||
|
||||
Use mc to add a (readonly or readwrite) user, by running ``` mc admin user add minio <access key> <secret key> <access level>```
|
||||
Use mc to add a (readonly or readwrite) user, by running ```mc admin user add minio <access key> <secret key> <access level>```
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
```bash
|
||||
root@ds1:~# mc admin user add minio spiderman peterparker readonly
|
||||
Added user `spiderman` successfully.
|
||||
root@ds1:~#
|
||||
@@ -119,7 +120,7 @@ root@ds1:~#
|
||||
|
||||
Confirm by listing your users (_admin is excluded from the list_):
|
||||
|
||||
```
|
||||
```bash
|
||||
root@node1:~# mc admin user list minio
|
||||
enabled spiderman readonly
|
||||
root@node1:~#
|
||||
@@ -133,7 +134,7 @@ The simplest permission scheme is "on or off". Either a bucket has a policy, or
|
||||
|
||||
After **no** policy, the most restrictive policy you can attach to a bucket is "download". This policy will allow authenticated users to download contents from the bucket. Apply the "download" policy to a bucket by running ```mc policy download minio/<bucket name>```, i.e.:
|
||||
|
||||
```
|
||||
```bash
|
||||
root@ds1:# mc policy download minio/comics
|
||||
Access permission for `minio/comics` is set to `download`
|
||||
root@ds1:#
|
||||
@@ -154,7 +155,7 @@ I tested the S3 mount using [goofys](https://github.com/kahing/goofys), "a high-
|
||||
|
||||
First, I created ~/.aws/credentials, as follows:
|
||||
|
||||
```
|
||||
```ini
|
||||
[default]
|
||||
aws_access_key_id=spiderman
|
||||
aws_secret_access_key=peterparker
|
||||
@@ -164,7 +165,7 @@ And then I ran (_in the foreground, for debugging_), ```goofys --f -debug_s3 --d
|
||||
|
||||
To permanently mount an S3 bucket using goofys, I'd add something like this to /etc/fstab:
|
||||
|
||||
```
|
||||
```bash
|
||||
goofys#bucket /mnt/mountpoint fuse _netdev,allow_other,--file-mode=0666 0 0
|
||||
```
|
||||
|
||||
@@ -172,4 +173,4 @@ goofys#bucket /mnt/mountpoint fuse _netdev,allow_other,--file-mode=
|
||||
[^2]: Some applications (_like [NextCloud](/recipes/nextcloud/)_) can natively mount S3 buckets
|
||||
[^3]: Some backup tools (_like [Duplicity](/recipes/duplicity/)_) can backup directly to S3 buckets
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -1,207 +0,0 @@
|
||||
hero: Kubernetes. The hero we deserve.
|
||||
|
||||
!!! danger "This recipe is a work in progress"
|
||||
This recipe is **incomplete**, and is featured to align the [sponsors](https://github.com/sponsors/funkypenguin)'s "premix" repository with the cookbook. "_premix_" is a private git repository available to [GitHub sponsors](https://github.com/sponsors/funkypenguin), which includes all the necessary .yml files for all published recipes. This means that sponsors can launch any recipe with just a `git pull` and a `kubectl create -f *.yml` 👍
|
||||
|
||||
So... There may be errors and inaccuracies. Jump into [Discord](http://chat.funkypenguin.co.nz) if you're encountering issues 😁
|
||||
|
||||
# MQTT broker
|
||||
|
||||
I use Elias Kotlyar's [excellent custom firmware](https://github.com/EliasKotlyar/Xiaomi-Dafang-Hacks) for Xiaomi DaFang/XiaoFang cameras, enabling RTSP, MQTT, motion tracking, and other features, integrating directly with [Home Assistant](/recipes/homeassistant/).
|
||||
|
||||
There's currently a [mysterious bug](https://github.com/EliasKotlyar/Xiaomi-Dafang-Hacks/issues/638) though, which prevents TCP communication between Home Assistant and the camera, when MQTT services are enabled on the camera and the mqtt broker runs on the same Raspberry Pi as Home Assistant, using [Hass.io](https://www.home-assistant.io/hassio/).
|
||||
|
||||
A workaround to this bug is to run an MQTT broker **external** to the raspberry pi, which makes the whole problem GoAway(tm). Since an MQTT broker is a single, self-contained container, I've written this recipe as an introduction to our Kubernetes cluster design.
|
||||
|
||||

|
||||
|
||||
[MQTT](https://mqtt.org/faq) stands for MQ Telemetry Transport. It is a publish/subscribe, extremely simple and lightweight messaging protocol, designed for constrained devices and low-bandwidth, high-latency or unreliable networks. The design principles are to minimise network bandwidth and device resource requirements whilst also attempting to ensure reliability and some degree of assurance of delivery. These principles also turn out to make the protocol ideal of the emerging “machine-to-machine” (M2M) or “Internet of Things” world of connected devices, and for mobile applications where bandwidth and battery power are at a premium.
|
||||
|
||||
## Ingredients
|
||||
|
||||
1. A [Kubernetes cluster](/kubernetes/cluster/)
|
||||
|
||||
## Preparation
|
||||
|
||||
### Create data locations
|
||||
|
||||
Although we could simply bind-mount local volumes to a local Kubuernetes cluster, since we're targetting a cloud-based Kubernetes deployment, we only need a local path to store the YAML files which define the various aspects of our Kubernetes deployment.
|
||||
|
||||
```
|
||||
mkdir /var/data/config/mqtt
|
||||
```
|
||||
|
||||
### Create namespace
|
||||
|
||||
We use Kubernetes namespaces for service discovery and isolation between our stacks, so create a namespace for the mqtt stack by creating the following .yaml:
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/mqtt/namespace.yml
|
||||
apiVersion: v1
|
||||
kind: Namespace
|
||||
metadata:
|
||||
name: mqtt
|
||||
EOF
|
||||
kubectl create -f /var/data/mqtt/namespace.yaml
|
||||
```
|
||||
|
||||
### Create persistent volume claim
|
||||
|
||||
Persistent volume claims are a streamlined way to create a persistent volume and assign it to a container in a pod. Create a claim for the certbot data:
|
||||
|
||||
```yaml
|
||||
cat <<EOF > /var/data/mqtt/persistent-volumeclaim.yml
|
||||
kind: PersistentVolumeClaim
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: mqtt-volumeclaim
|
||||
namespace: mqtt
|
||||
spec:
|
||||
accessModes:
|
||||
- ReadWriteOnce
|
||||
resources:
|
||||
requests:
|
||||
storage: 1Gi
|
||||
EOF
|
||||
kubectl create -f /var/data/mqtt/mqtt-volumeclaim.yaml
|
||||
```
|
||||
|
||||
### Create nodeport service
|
||||
|
||||
I like to expose my services using nodeport (_limited to ports 30000-32767_), and then use an external haproxy load balancer to make these available externally. (_This avoids having to pay per-port changes for a loadbalancer from the cloud provider_)
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/mqtt/service-nodeport.yml
|
||||
kind: Service
|
||||
apiVersion: v1
|
||||
metadata:
|
||||
name: mqtt-nodeport
|
||||
namespace: mqtt
|
||||
spec:
|
||||
selector:
|
||||
app: mqtt
|
||||
type: NodePort
|
||||
ports:
|
||||
- name: mqtts
|
||||
port: 8883
|
||||
protocol: TCP
|
||||
nodePort : 30883
|
||||
EOF
|
||||
kubectl create -f /var/data/mqtt/service-nodeport.yml
|
||||
```
|
||||
|
||||
### Create secrets
|
||||
|
||||
It's not always desirable to have sensitive data stored in your .yml files. Maybe you want to check your config into a git repository, or share it. Using Kubernetes Secrets means that you can create "secrets", and use these in your deployments by name, without exposing their contents.
|
||||
|
||||
```
|
||||
echo -n "myapikeyissosecret" > cloudflare-key.secret
|
||||
echo -n "myemailaddress" > cloudflare-email.secret
|
||||
echo -n "myemailaddress" > letsencrypt-email.secret
|
||||
|
||||
kubectl create secret -n mqtt generic mqtt-credentials \
|
||||
--from-file=cloudflare-key.secret \
|
||||
--from-file=cloudflare-email.secret \
|
||||
--from-file=letsencrypt-email.secret
|
||||
```
|
||||
|
||||
!!! tip "Why use `echo -n`?"
|
||||
Because. See [my blog post here](https://www.funkypenguin.co.nz/beware-the-hidden-newlines-in-kubernetes-secrets/) for the pain of hunting invisible newlines, that's why!
|
||||
|
||||
## Serving
|
||||
|
||||
### Create deployment
|
||||
|
||||
Now that we have a volume, a service, and a namespace, we can create a deployment for the mqtt pod. Note below the use of volume mounts, environment variables, as well as the secrets.
|
||||
|
||||
--8<-- "premix-cta.md"
|
||||
|
||||
```
|
||||
cat <<EOF > /var/data/mqtt/mqtt.yml
|
||||
apiVersion: extensions/v1beta1
|
||||
kind: Deployment
|
||||
metadata:
|
||||
namespace: mqtt
|
||||
name: mqtt
|
||||
labels:
|
||||
app: mqtt
|
||||
spec:
|
||||
replicas: 1
|
||||
selector:
|
||||
matchLabels:
|
||||
app: mqtt
|
||||
template:
|
||||
metadata:
|
||||
labels:
|
||||
app: mqtt
|
||||
spec:
|
||||
containers:
|
||||
- image: funkypenguin/mqtt-certbot-dns
|
||||
imagePullPolicy: Always
|
||||
# only uncomment these to get the container to run so that we can transfer files into the PV
|
||||
# command: [ "/bin/sleep" ]
|
||||
# args: [ "1h" ]
|
||||
env:
|
||||
- name: DOMAIN
|
||||
value: "*.funkypenguin.co.nz"
|
||||
- name: EMAIL
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: mqtt-credentials
|
||||
key: letsencrypt-email.secret
|
||||
- name: CLOUDFLARE_EMAIL
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: mqtt-credentials
|
||||
key: cloudflare-email.secret
|
||||
- name: CLOUDFLARE_KEY
|
||||
valueFrom:
|
||||
secretKeyRef:
|
||||
name: mqtt-credentials
|
||||
key: cloudflare-key.secret
|
||||
# uncomment this to test LetsEncrypt validations
|
||||
# - name: TESTCERT
|
||||
# value: "true"
|
||||
name: mqtt
|
||||
resources:
|
||||
requests:
|
||||
memory: "50Mi"
|
||||
cpu: "0.1"
|
||||
volumeMounts:
|
||||
# We need the LE certs to persist across reboots to avoid getting rate-limited (bad, bad)
|
||||
- name: mqtt-volumeclaim
|
||||
mountPath: /etc/letsencrypt
|
||||
# A configmap for the mosquitto.conf file
|
||||
- name: mosquitto-conf
|
||||
mountPath: /mosquitto/conf/mosquitto.conf
|
||||
subPath: mosquitto.conf
|
||||
# A configmap for the mosquitto passwd file
|
||||
- name: mosquitto-passwd
|
||||
mountPath: /mosquitto/conf/passwd
|
||||
subPath: passwd
|
||||
volumes:
|
||||
- name: mqtt-volumeclaim
|
||||
persistentVolumeClaim:
|
||||
claimName: mqtt-volumeclaim
|
||||
- name: mosquitto-conf
|
||||
configMap:
|
||||
name: mosquitto.conf
|
||||
- name: mosquitto-passwd
|
||||
configMap:
|
||||
name: passwd
|
||||
EOF
|
||||
kubectl create -f /var/data/mqtt/mqtt.yml
|
||||
```
|
||||
|
||||
Check that your deployment is running, with `kubectl get pods -n mqtt`. After a minute or so, you should see a "Running" pod, as illustrated below:
|
||||
|
||||
```
|
||||
[davidy:~/Documents/Personal/Projects/mqtt-k8s] 130 % kubectl get pods -n mqtt
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
mqtt-65f4d96945-bjj44 1/1 Running 0 5m
|
||||
[davidy:~/Documents/Personal/Projects/mqtt-k8s] %
|
||||
```
|
||||
|
||||
To actually **use** your new MQTT broker, you'll need to connect to any one of your nodes (`kubectl get nodes -o wide`) on port 30883 (_the nodeport service we created earlier_). More info on that, and a loadbalancer design, to follow shortly :)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
@@ -1,4 +1,3 @@
|
||||
|
||||
---
|
||||
description: Network resource monitoring tool for quick analysis
|
||||
---
|
||||
@@ -23,7 +22,7 @@ Depending on what you want to monitor, you'll want to install munin-node. On Ubu
|
||||
|
||||
On CentOS Atomic, of course, you can't install munin-node directly, but you can run it as a containerized instance. In this case, you can't use swarm since you need the container running in privileged mode, so launch a munin-node container on each atomic host using:
|
||||
|
||||
```
|
||||
```bash
|
||||
docker run -d --name munin-node --restart=always \
|
||||
--privileged --net=host \
|
||||
-v /:/rootfs:ro \
|
||||
@@ -38,7 +37,7 @@ docker run -d --name munin-node --restart=always \
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/munin:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/munin
|
||||
cd /var/data/munin
|
||||
mkdir -p {log,lib,run,cache}
|
||||
@@ -48,7 +47,7 @@ mkdir -p {log,lib,run,cache}
|
||||
|
||||
Create /var/data/config/munin/munin.env, and populate with the following variables. Use the OAUTH2 variables if you plan to use an [oauth2_proxy](/reference/oauth_proxy/) to protect munin, and set at a **minimum** the `MUNIN_USER`, `MUNIN_PASSWORD`, and `NODES` values:
|
||||
|
||||
```
|
||||
```bash
|
||||
# Use these if you plan to protect the webUI with an oauth_proxy
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
@@ -132,4 +131,4 @@ Log into your new instance at https://**YOUR-FQDN**, with user and password pass
|
||||
|
||||
[^1]: If you wanted to expose the Munin UI directly, you could remove the oauth2_proxy from the design, and move the traefik-related labels directly to the munin container. You'd also need to add the traefik_public network to the munin container.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -5,7 +5,8 @@ description: Share docs. Backup files. Share stuff.
|
||||
# NextCloud
|
||||
|
||||
[NextCloud](https://www.nextcloud.org/) (_a [fork of OwnCloud](https://owncloud.org/blog/owncloud-statement-concerning-the-formation-of-nextcloud-by-frank-karlitschek/), led by original developer Frank Karlitschek_) is a suite of client-server software for creating and using file hosting services. It is functionally similar to Dropbox, although Nextcloud is free and open-source, allowing anyone to install and operate it on a private server.
|
||||
- https://en.wikipedia.org/wiki/Nextcloud
|
||||
|
||||
- <https://en.wikipedia.org/wiki/Nextcloud>
|
||||
|
||||

|
||||
|
||||
@@ -19,7 +20,7 @@ This recipe is based on the official NextCloud docker image, but includes seprat
|
||||
|
||||
We'll need several directories for [static data](/reference/data_layout/#static-data) to bind-mount into our container, so create them in /var/data/nextcloud (_so that they can be [backed up](/recipes/duplicity/)_)
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/nextcloud
|
||||
cd /var/data/nextcloud
|
||||
mkdir -p {html,apps,config,data,database-dump}
|
||||
@@ -27,17 +28,17 @@ mkdir -p {html,apps,config,data,database-dump}
|
||||
|
||||
Now make **more** directories for [runtime data](/reference/data_layout/#runtime-data) (_so that they can be **not** backed-up_):
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/runtime/nextcloud
|
||||
cd /var/data/runtime/nextcloud
|
||||
mkdir -p {db,redis}
|
||||
```
|
||||
|
||||
|
||||
### Prepare environment
|
||||
|
||||
Create nextcloud.env, and populate with the following variables
|
||||
```
|
||||
|
||||
```bash
|
||||
NEXTCLOUD_ADMIN_USER=admin
|
||||
NEXTCLOUD_ADMIN_PASSWORD=FVuojphozxMVyaYCUWomiP9b
|
||||
MYSQL_HOST=db
|
||||
@@ -51,7 +52,7 @@ MYSQL_PASSWORD=set to something secure>
|
||||
|
||||
Now create a **separate** nextcloud-db-backup.env file, to capture the environment variables necessary to perform the backup. (_If the same variables are shared with the mariadb container, they [cause issues](https://discourse.geek-kitchen.funkypenguin.co.nz/t/nextcloud-funky-penguins-geek-cookbook/254/3?u=funkypenguin) with database access_)
|
||||
|
||||
````
|
||||
````bash
|
||||
# For database backup (keep 7 days daily backups)
|
||||
MYSQL_PWD=<set to something secure, same as MYSQL_ROOT_PASSWORD above>
|
||||
MYSQL_USER=root
|
||||
@@ -163,8 +164,8 @@ Log into your new instance at https://**YOUR-FQDN**, with user "admin" and the p
|
||||
|
||||
To make NextCloud [a little snappier](https://docs.nextcloud.com/server/13/admin_manual/configuration_server/caching_configuration.html), edit ```/var/data/nextcloud/config/config.php``` (_now that it's been created on the first container launch_), and add the following:
|
||||
|
||||
```
|
||||
'redis' => array(
|
||||
```bash
|
||||
'redis' => array(
|
||||
'host' => 'redis',
|
||||
'port' => 6379,
|
||||
),
|
||||
@@ -178,31 +179,31 @@ Huzzah! NextCloud supports [service discovery for CalDAV/CardDAV](https://tools.
|
||||
|
||||
We (_and anyone else using the [NextCloud Docker image](https://hub.docker.com/_/nextcloud/)_) are using an SSL-terminating reverse proxy ([Traefik](/ha-docker-swarm/traefik/)) in front of our NextCloud container. In fact, it's not **possible** to setup SSL **within** the NextCloud container.
|
||||
|
||||
When using a reverse proxy, your device requests a URL from your proxy (https://nextcloud.batcave.com/.well-known/caldav), and the reverse proxy then passes that request **unencrypted** to the internal URL of the NextCloud instance (i.e., http://172.16.12.123/.well-known/caldav)
|
||||
When using a reverse proxy, your device requests a URL from your proxy (<https://nextcloud.batcave.com/.well-known/caldav>), and the reverse proxy then passes that request **unencrypted** to the internal URL of the NextCloud instance (i.e., <http://172.16.12.123/.well-known/caldav>)
|
||||
|
||||
The Apache webserver on the NextCloud container (_knowing it was spoken to via HTTP_), responds with a 301 redirect to http://nextcloud.batcave.com/remote.php/dav/. See the problem? You requested an **HTTPS** (_encrypted_) url, and in return, you received a redirect to an **HTTP** (_unencrypted_) URL. Any sensible client (_iOS included_) will refuse such schenanigans.
|
||||
The Apache webserver on the NextCloud container (_knowing it was spoken to via HTTP_), responds with a 301 redirect to <http://nextcloud.batcave.com/remote.php/dav/>. See the problem? You requested an **HTTPS** (_encrypted_) url, and in return, you received a redirect to an **HTTP** (_unencrypted_) URL. Any sensible client (_iOS included_) will refuse such schenanigans.
|
||||
|
||||
To correct this, we need to tell NextCloud to always redirect the .well-known URLs to an HTTPS location. This can only be done **after** deploying NextCloud, since it's only on first launch of the container that the .htaccess file is created in the first place.
|
||||
|
||||
To make NextCloud service discovery work with Traefik reverse proxy, edit ```/var/data/nextcloud/html/.htaccess```, and change this:
|
||||
|
||||
```
|
||||
```bash
|
||||
RewriteRule ^\.well-known/carddav /remote.php/dav/ [R=301,L]
|
||||
RewriteRule ^\.well-known/caldav /remote.php/dav/ [R=301,L]
|
||||
```
|
||||
|
||||
To this:
|
||||
|
||||
```
|
||||
```bash
|
||||
RewriteRule ^\.well-known/carddav https://%{SERVER_NAME}/remote.php/dav/ [R=301,L]
|
||||
RewriteRule ^\.well-known/caldav https://%{SERVER_NAME}/remote.php/dav/ [R=301,L]
|
||||
```
|
||||
|
||||
Then restart your container with ```docker service update nextcloud_nextcloud --force``` to restart apache.
|
||||
|
||||
Your can test for success by running ```curl -i https://nextcloud.batcave.org/.well-known/carddav```. You should get a 301 redirect to your equivalent of https://nextcloud.batcave.org/remote.php/dav/, as below:
|
||||
Your can test for success by running ```curl -i https://nextcloud.batcave.org/.well-known/carddav```. You should get a 301 redirect to your equivalent of <https://nextcloud.batcave.org/remote.php/dav/>, as below:
|
||||
|
||||
```
|
||||
```bash
|
||||
[davidy:~] % curl -i https://nextcloud.batcave.org/.well-known/carddav
|
||||
HTTP/2 301
|
||||
content-type: text/html; charset=iso-8859-1
|
||||
@@ -215,4 +216,4 @@ Note that this .htaccess can be overwritten by NextCloud, and you may have to re
|
||||
[^1]: Since many of my other recipes use PostgreSQL, I'd have preferred to use Postgres over MariaDB, but MariaDB seems to be the [preferred database type](https://github.com/nextcloud/server/issues/5912).
|
||||
[^2]: I'm [not the first user](https://github.com/nextcloud/docker/issues/528) to stumble across the service discovery bug with reverse proxies.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -6,11 +6,10 @@ description: CGM data with an API, for diabetic quality-of-life improvements
|
||||
|
||||
Nightscout is "*...an open source, DIY project that allows real time access to a CGM data via personal website, smartwatch viewers, or apps and widgets available for smartphones*"
|
||||
|
||||
!!! question "Yeah, but what's a CGM?"
|
||||
A CGM is a "continuos glucose monitor" :drop_of_blood: - If you have a blood-sugar-related disease (*i.e. diabetes*), you might wear a CGM in order to retrieve blood-glucose level readings, to inform your treatment.
|
||||
|
||||
NightScout frees you from the CGM's supplier's limited and proprietary app, and unlocks advanced charting, alarming, and sharing features :muscle:
|
||||
!!! question "Yeah, but what's a CGM?"
|
||||
A CGM is a "continuos glucose monitor" :drop_of_blood: - If you have a blood-sugar-related disease (*i.e. diabetes*), you might wear a CGM in order to retrieve blood-glucose level readings, to inform your treatment.
|
||||
|
||||
NightScout frees you from the CGM's supplier's limited and proprietary app, and unlocks advanced charting, alarming, and sharing features :muscle:
|
||||
|
||||

|
||||
|
||||
@@ -25,14 +24,15 @@ Most NightScout users will deploy to Heroko, using MongoDB Atlas, which is a [we
|
||||
### Setup data locations
|
||||
|
||||
First we create a directory to hold Nightscout's database, as well as database backups:
|
||||
```
|
||||
|
||||
```bash
|
||||
mkdir -p /var/data/runtime/nightscout/database # excluded from automated backups
|
||||
mkdir -p /var/data/nightscout/database # included in automated backups
|
||||
```
|
||||
|
||||
### Create env file
|
||||
|
||||
NightScout is configured entirely using environment variables, so create something like this as `/var/data/config/nightscout/nightscout.env`:
|
||||
NightScout is configured entirely using environment variables, so create something like this as `/var/data/config/nightscout/nightscout.env`:
|
||||
|
||||
!!! warning
|
||||
Your variables may vary significantly from what's illustrated below, and it's best to read up and understand exactly what each option does.
|
||||
@@ -164,7 +164,6 @@ networks:
|
||||
|
||||
Launch the nightscout stack by running ```docker stack deploy nightscout -c <path -to-docker-compose.yml>```
|
||||
|
||||
|
||||
[^1]: Most of the time, you'll need an app which syncs to Nightscout, and these apps won't support OIDC auth, so this recipe doesn't take into account any sort of authentication using [Traefik Forward Auth](/ha-docker-swarm/traefik-forward-auth/). Instead, NightScout is secured entirely with your `API_SECRET` above (*although it is possible to add more users once you're an admin*)
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -30,7 +30,7 @@ What you'll end up with is a directory structure which will allow integration wi
|
||||
|
||||
We'll need several directories to bind-mount into our container, so create them in /var/data/openldap:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/openldap/openldap
|
||||
mkdir /var/data/runtime/openldap/
|
||||
```
|
||||
@@ -42,7 +42,7 @@ mkdir /var/data/runtime/openldap/
|
||||
|
||||
Create /var/data/openldap/openldap.env, and populate with the following variables, customized for your own domain structure. Take care with LDAP_DOMAIN, this is core to your directory structure, and can't easily be changed later.
|
||||
|
||||
```
|
||||
```bash
|
||||
LDAP_DOMAIN=batcave.gotham
|
||||
LDAP_ORGANISATION=BatCave Inc
|
||||
LDAP_ADMIN_PASSWORD=supermansucks
|
||||
@@ -67,7 +67,7 @@ Create ```/var/data/openldap/lam/config/config.cfg``` as follows:
|
||||
|
||||
???+ note "Much scroll, very text. Click here to collapse it for better readability"
|
||||
|
||||
```
|
||||
```bash
|
||||
# password to add/delete/rename configuration profiles (default: lam)
|
||||
password: {SSHA}D6AaX93kPmck9wAxNlq3GF93S7A= R7gkjQ==
|
||||
|
||||
@@ -137,7 +137,7 @@ Create yours profile (_you chose a default profile in config.cfg above, remember
|
||||
|
||||
???+ note "Much scroll, very text. Click here to collapse it for better readability"
|
||||
|
||||
```
|
||||
```bash
|
||||
# LDAP Account Manager configuration
|
||||
#
|
||||
# Please do not modify this file manually. The configuration can be done completely by the LAM GUI.
|
||||
@@ -392,7 +392,7 @@ networks:
|
||||
|
||||
Create **another** stack config file (```/var/data/config/openldap/auth.yml```) containing just the auth_internal network, and a dummy container:
|
||||
|
||||
```
|
||||
```yaml
|
||||
version: "3.2"
|
||||
|
||||
# What is this?
|
||||
@@ -417,9 +417,6 @@ networks:
|
||||
- subnet: 172.16.39.0/24
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
## Serving
|
||||
|
||||
### Launch OpenLDAP stack
|
||||
@@ -436,4 +433,4 @@ Create your users using the "**New User**" button.
|
||||
|
||||
[^1]: [The KeyCloak](/recipes/keycloak/authenticate-against-openldap/) recipe illustrates how to integrate KeyCloak with your LDAP directory, giving you a cleaner interface to manage users, and a raft of SSO / OAuth features.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -21,7 +21,7 @@ Using a smartphone app, OwnTracks allows you to collect and analyse your own loc
|
||||
|
||||
We'll need a directory so store OwnTracks' data , so create ```/var/data/owntracks```:
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/owntracks
|
||||
```
|
||||
|
||||
@@ -29,7 +29,7 @@ mkdir /var/data/owntracks
|
||||
|
||||
Create owntracks.env, and populate with the following variables
|
||||
|
||||
```
|
||||
```bash
|
||||
OAUTH2_PROXY_CLIENT_ID=
|
||||
OAUTH2_PROXY_CLIENT_SECRET=
|
||||
OAUTH2_PROXY_COOKIE_SECRET=
|
||||
@@ -107,4 +107,4 @@ Log into your new instance at https://**YOUR-FQDN**, with user "root" and the pa
|
||||
[^2]: I'm using my own image rather than owntracks/recorderd, because of a [potentially swarm-breaking bug](https://github.com/owntracks/recorderd/issues/14) I found in the official container. If this gets resolved (_or if I was mistaken_) I'll update the recipe accordingly.
|
||||
[^3]: By default, you'll get a fully accessible, unprotected MQTT broker. This may not be suitable for public exposure, so you'll want to look into securing mosquitto with TLS and ACLs.
|
||||
|
||||
--8<-- "recipe-footer.md"
|
||||
--8<-- "recipe-footer.md"
|
||||
|
||||
@@ -8,7 +8,6 @@ Paper is a nightmare. Environmental issues aside, there’s no excuse for it in
|
||||
|
||||

|
||||
|
||||
|
||||
--8<-- "recipe-standard-ingredients.md"
|
||||
|
||||
## Preparation
|
||||
@@ -17,7 +16,7 @@ Paper is a nightmare. Environmental issues aside, there’s no excuse for it in
|
||||
|
||||
We'll need a folder to store a docker-compose configuration file and an associated environment file. If you're following my filesystem layout, create `/var/data/config/paperless` (*for the config*). We'll also need to create `/var/data/paperless` and a few subdirectories (*for the metadata*). Lastly, we need a directory for the database backups to reside in as well.
|
||||
|
||||
```
|
||||
```bash
|
||||
mkdir /var/data/config/paperless
|
||||
mkdir /var/data/paperless
|
||||
mkdir /var/data/paperless/consume
|
||||
@@ -29,13 +28,13 @@ mkdir /var/data/paperless/database-dump
|
||||
```
|
||||
|
||||
!!! question "Which is it, Paperless or Paperless-NG?"
|
||||
Technically the name of the application is `paperless-ng`. However, the [original Paperless project](https://github.com/the-paperless-project/paperless) has been archived and the author recommends Paperless NG. So, to save some typing, we'll just call it "Paperless". Additionally, if you use the automated tooling in the Premix Repo, Ansible *really* doesn't like the hypen.
|
||||
Technically the name of the application is `paperless-ng`. However, the [original Paperless project](https://github.com/the-paperless-project/paperless) has been archived and the author recommends Paperless NG. So, to save some typing, we'll just call it "Paperless". Additionally, if you use the automated tooling in the Premix Repo, Ansible *really* doesn't like the hypen.
|
||||
|
||||
### Create environment
|
||||
|
||||
To stay consistent with the other recipes, we'll create a file to store environemnt variables in. There's more than 1 service in this stack, but we'll only create one one environment file that will be used by the web server (more on this later).
|
||||
|
||||
```
|
||||
```bash
|
||||
cat << EOF > /var/data/config/paperless/paperless.env
|
||||
PAPERLESS_TIME_ZONE:<timezone>
|
||||
PAPERLESS_ADMIN_USER=<admin_user>
|
||||
@@ -48,6 +47,7 @@ PAPERLESS_TIKA_GOTENBERG_ENDPOINT=http://gotenberg:3000
|
||||
PAPERLESS_TIKA_ENDPOINT=http://tika:9998
|
||||
EOF
|
||||
```
|
||||
|
||||
You'll need to replace some of the text in the snippet above:
|
||||
|
||||
* `<timezone>` - Replace with an entry from [the timezone database](https://en.wikipedia.org/wiki/List_of_tz_database_time_zones) (eg: America/New_York)
|
||||
@@ -158,13 +158,14 @@ networks:
|
||||
- subnet: 172.16.58.0/24
|
||||
|
||||
```
|
||||
|
||||
You'll notice that there are several items under "services" in this stack. Let's take a look at what each one does:
|
||||
|
||||
* broker - Redis server that other services use to share data
|
||||
* webserver - The UI that you will use to add and view documents, edit document metadata, and configure the application settings.
|
||||
* gotenburg - Tool that facilitates converting MS Office documents, HTML, Markdown and other document types to PDF
|
||||
* tika - The OCR engine that extracts text from image-only documents
|
||||
* db - PostgreSQL database engine to store metadata for all the documents. [^2]
|
||||
* db - PostgreSQL database engine to store metadata for all the documents. [^2]
|
||||
* db-backup - Service to dump the PostgreSQL database to a backup file on disk once per day
|
||||
|
||||
## Serving
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user